


Os mecanismos de pesquisa tornaram-se uma ferramenta padrão para localizar informações de que o nome do mais comum agora é um substituto para o próprio ato de pesquisar - portanto, "pesquisar" algo. No entanto, a vastidão de informações disponíveis por meio de mecanismos de pesquisa pode ser um obstáculo ao consultar detalhes, como pesquisar conceitos científicos e pesquisas. Retornar resultados úteis e relevantes sem perder novas informações é um equilíbrio desafiador, mas novas ferramentas e recursos de design estão melhorando o processo.
Os pesquisadores científicos conhecem muito bem esse desafio e, sem as ferramentas certas, pode ser mais difícil encontrar publicações e materiais relevantes. Retorne resultados muito amplos e você não consiga encontrar o que realmente importa. Retorne respostas muito focadas e você pode perder uma nova ideia importante.
Determinar o ponto ideal para a pesquisa científica pode ser um desafio, mas felizmente não está fora de alcance.
Recall vs. precisão nos mecanismos de pesquisa
Para entender a pesquisa científica, primeiro é importante entender as maneiras pelas quais os mecanismos de pesquisa funcionam. O Google, por exemplo, prioriza o recall. Dito de outra forma, ele maximiza o número de respostas que podem ser retornadas para uma consulta. Não há preocupação de que o usuário precise revisar todas as respostas possíveis, e a tecnologia tenta classificar os resultados por relevância para que as informações mais valiosas para o usuário estejam no topo da página de resultados.
Por outro lado, outros mecanismos de pesquisa podem priorizar a precisão, o que maximiza as respostas mais relevantes para uma determinada consulta. Esse tipo de pesquisa é semelhante ao uso da pesquisa de catálogo de uma biblioteca: há um conjunto estabelecido de resultados com vários campos para especificação de pesquisa, como título, autor e data. Maximizar a precisão pode aumentar suas chances de obter um conjunto de resultados gerenciável, mas também aumenta a possibilidade de perder algo que esteja fora do ajuste da pesquisa de precisão.
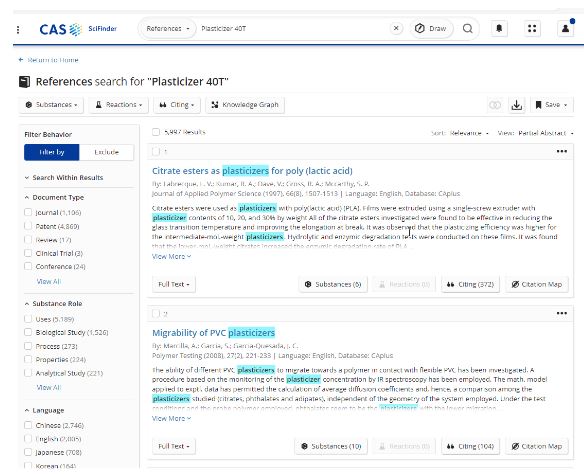
Vamos explorar um exemplo dessa diferença: se um usuário pesquisar a consulta "Plastificante 40T", um mecanismo de pesquisa típico não reconhecerá que toda a consulta representa uma substância comercial única. Priorizando o recall, ele retornará resultados genéricos para plastificantes que não incluem "40T". O usuário terá que realizar uma segunda consulta, refinando para incluir "40T" nos resultados.
Uma pesquisa mais focada na precisão e com reconhecimento científico, por exemplo, via CAS SciFinder(R), avalia a consulta em relação aos dados de ontologia selecionados e reconhece isso como uma nova entidade de substância. Portanto, ele retorna imediatamente os resultados para a substância específica Plastificante 40T, mesmo que um nome diferente para essa substância seja usado no texto do artigo (consulte a Figura 1).
Projetar os recursos de pesquisa corretos é fundamental para o que fazemos no CAS, e é por isso que o CAS SciFinder pode reconhecer facilmente uma nova substância em um termo com conexões de pesquisa científica. As ferramentas de pesquisa desenvolvidas por cientistas são inerentemente mais sensíveis à terminologia usada por colegas pesquisadores. No entanto, a busca por uma substância comercial ainda é um exercício bastante definido. O que acontece quando um pesquisador está procurando relevância, mas também amplitude relacionada a uma doença, campo de estudo ou conceito?
Como encontrar o ponto ideal do mecanismo de pesquisa
Uma maneira comum de equilibrar amplitude e profundidade é por meio da pesquisa booleana que utiliza "e", "ou" e outras conjunções para conectar termos. O uso de aspas para bloquear os termos de pesquisa também pode ajudar a refinar as consultas para obter resultados mais precisos.
Independentemente de como eles elaboram uma determinada consulta, os pesquisadores ainda podem encontrar o ponto ideal com um mecanismo de pesquisa que usa dados estruturados e reconhece sequências de texto com vários termos. Os dados estruturados terão um formato consistente e serão organizados em coleções de dados com base em suas características. O algoritmo de pesquisa pode identificar e avaliar com mais eficiência quais resultados retornar. Reconhecer cadeias de caracteres de texto exclusivas de vários termos como entidades únicas e pesquisar como tal reduz os resultados não relevantes que seriam gerados pela pesquisa individual dos fragmentos de termo.
Como se desenvolve esse tipo de corpus de conteúdo? Por meio de curadoria cuidadosa e do uso de ontologias para construir uma compreensão refinada das consultas do usuário. O CAS ContentCollection TM, por exemplo, é o maior repositório de informações científicas com curadoria humana, e nossas políticas de curadoria identificam os termos e substâncias mais relevantes para criar entradas indexadas exclusivas. Devido à curadoria, os resultados da pesquisa não se limitam ao conteúdo de um título ou resumo de uma determinada publicação.
Nossa indexação inclui conceitos e terminologias das seções experimentais da literatura científica que são específicos para a novidade da ciência nessa publicação. Por exemplo, uma seção introdutória de um artigo de periódico pode definir um metacontexto de interesse para o autor - como a próxima cura revolucionária para uma determinada doença - mas a novidade real do artigo é um novo método analítico para avaliar um processo químico. Uma solução como o CAS SciFinder, que usa dados selecionados, se concentrará no método analítico, não no metacontexto, para responder melhor à consulta de um usuário.
Ontologias conectam as ideias certas para resultados relevantes
A maneira como construímos essas conexões é por meio de ontologias, que são coleções selecionadas de terminologia que incluem a captura de relacionamentos sinônimos. Esses relacionamentos fornecem uma lista refinada, mas ainda extensa, de termos a serem alavancados. Se um usuário pesquisar uma substância por um nome comercial, nossa ontologia incluirá variações de nomes químicos, outros nomes comerciais e até identificadores internos em registros de patentes. Sem essas conexões, um mecanismo de pesquisa típico não consegue identificar resultados relevantes.
É por isso que uma ferramenta de pesquisa criada por cientistas para cientistas pode impulsionar uma inovação mais eficiente – eles podem fornecer resultados mais relevantes mais rapidamente do que um mecanismo de pesquisa que prioriza a lembrança, e os dados capturam relações hierárquicas entre as principais terminologias.
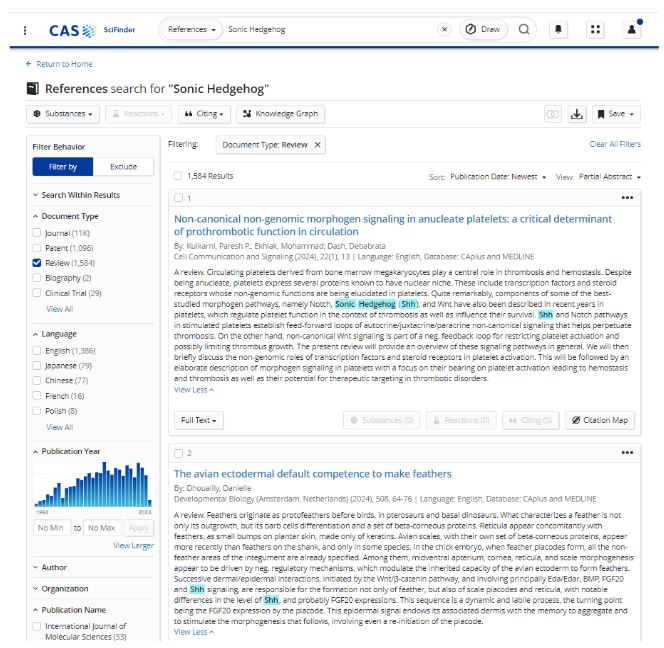
Por exemplo, pesquisar o termo Sonic Hedgehog no CAS SciFinder versus um mecanismo de pesquisa comum produz resultados marcadamente diferentes. O CAS SciFinder reconhece imediatamente isso como uma proteína e retorna publicações científicas relevantes (veja a Figura 3). Um mecanismo de busca geral, no entanto, retorna o conhecido personagem de videogame, não a informação de proteína que um cientista estaria procurando.
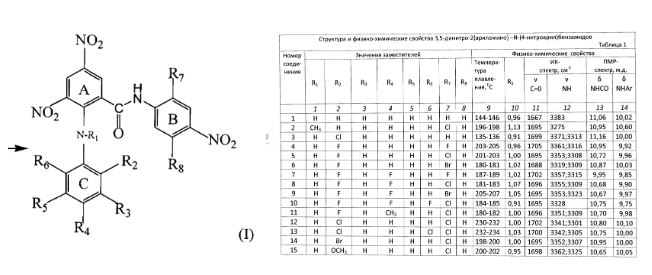
Além das ontologias, a indexação com curadoria humana permite ainda a descoberta onde os algoritmos geralmente falham. Um ser humano pode reconhecer as conexões entre um código e a estrutura química e construir relacionamentos que definem uma entidade química que as abordagens de indexação com curadoria não humana podem perder. Isso permite a captura de dados em diagramas, como moléculas e compostos, e conecta essas informações a explicações que podem estar em tabelas, gráficos ou texto em outras partes da publicação (consulte a Figura 4).
Sem curadoria, um mecanismo de pesquisa típico deve contar com o reconhecimento óptico de caracteres (OCR) para gráficos e diagramas, e algo tão simples quanto uma resolução de imagem ruim pode levar à perda de uma descoberta importante. Soluções com curadoria humana, como as de nossas equipes no CAS, aproveitam o melhor da experiência humana com a velocidade e os avanços algorítmicos da tecnologia de ponta.
A qualidade dos dados é importante para o futuro da pesquisa
A pesquisa científica não é como procurar uma avaliação de restaurante local, e as instituições acadêmicas e comerciais se beneficiam das soluções que equilibram recall e precisão. À medida que o corpo de conhecimento cresce em qualquer campo científico, as capacidades de pesquisa precisam evoluir. Isso só vai se tornar mais crítico à medida que as ferramentas orientadas por IA se tornarem as soluções de pesquisa padrão. Grandes modelos de linguagem (LLMs) podem ter dificuldades com a pesquisa científica, a menos que sejam treinados nos dados adequados e tenham camadas de redes neurais para lidar com dados não textuais.
Com curadoria especializada, ontologias robustas e a capacidade de alavancar dados não textuais, soluções especializadas podem enfrentar o desafio de refinar e melhorar continuamente a pesquisa científica e as descobertas inovadoras.




