


搜索引擎已经成为一种用于定位信息的标准工具,而最常见的信息的名称现在是搜索行为的替代品——因此“谷歌搜索”某些东西。 然而,在查询诸如搜索科学概念和研究等具体信息时,通过搜索引擎获得的大量信息可能会成为障碍。 在不遗漏新信息的同时返回有用且相关的结果是一个具有挑战性的平衡,但新的工具和设计功能正在改进这一过程。
科研人员非常清楚这一挑战,如果没有合适的工具,就很难找到相关的出版物和材料。 返回的结果太宽泛,您无法找到真正重要的内容。 返回的答案过于狭隘,你可能会错过一个重要的新想法。
确定科学研究的最佳点可能具有挑战性,但幸运的是,这并非遥不可及。
搜索引擎中的召回率与精确度
要理解科学搜索,首先要了解搜索引擎的运作方式。 例如,谷歌优先考虑召回。 换句话说,它最大化了查询可能返回的答案数量。 无需担心用户需要查看每个可能的答案,并且该技术尝试按相关性对结果进行排名,以便对用户最有价值的信息位于结果页面的顶部。
相反,其他搜索引擎可以优先考虑精确度,从而最大限度地提高给定查询的最相关答案。 这种类型的搜索类似于使用图书馆的目录搜索:有一组已建立的结果,其中包含许多用于搜索规范的字段,例如标题、作者和日期。 最大化精度可以增加获得可管理结果集的机会,但它也增加了遗漏恰好在精度搜索调整范围之外的内容的可能性。
让我们来探讨一下这种差异的一个例子:如果用户搜索查询“增塑剂 40T”,典型的搜索引擎将无法识别整个查询代表一种独特的商业物质。 优先考虑召回,它将返回不包括“40T”的增塑剂的通用结果。用户将不得不进行第二次查询,细化以在结果中包含“40T”。
例如,通过CAS SciFinder(R)进行更精确、更科学的搜索,根据精选的本体数据评估查询,并将其识别为一种新的物质实体。 因此,即使文章文本中使用了该物质的不同名称,它也会立即返回特定物质 Plasticizer 40T 的结果(见图 1)。
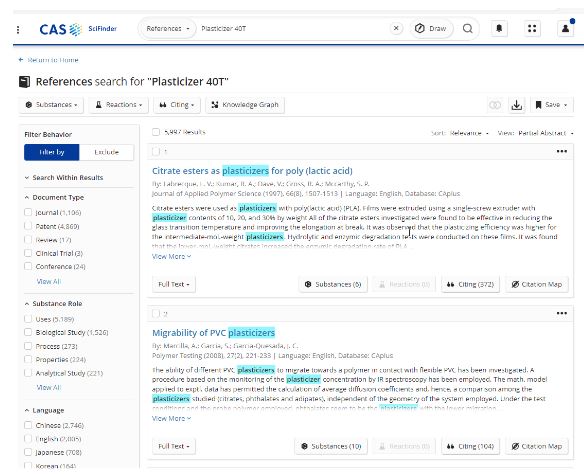
设计正确的搜索功能是 CAS 工作的核心,这就是为什么 CAS SciFinder 可以很容易地识别出与科研有联系的术语中的新物质。 由科学家开发的搜索工具本质上对研究人员使用的术语更敏感。 然而,寻找一种商业物质仍然是一项相当明确的工作。 当研究人员正在寻找与疾病、研究领域或概念相关的相关性和广度时,会发生什么?
如何找到搜索引擎的最佳位置
平衡广度和深度的一种常用方法是通过 布尔 搜索,该搜索利用“and”、“or”和其他连词来连接术语。 使用引号将搜索词锁定在一起还有助于优化查询以获得更精确的结果。
无论他们如何制作某个查询,研究人员仍然可以使用使用结构化数据并识别多词文本字符串的搜索引擎找到最佳位置。 结构化数据将具有一致的格式,并根据其特征组织成数据集合。 然后,搜索算法可以更有效地识别和评估要返回的结果。 将唯一的多术语文本字符串识别为单个实体并进行搜索,可以减少通过单独搜索术语片段生成的不相关结果。
如何开发这种类型的内容语料库? 通过仔细的策展和使用 本体 来构建对用户查询的精细理解。 例如, CAS 内容合集TM 是最大的人工管理的科学信息库,我们的管理政策会识别最相关的术语和内容,以创建独特的索引条目。 由于策展,搜索结果不限于给定出版物的标题或摘要的内容。
我们的索引包括科学文献实验部分的概念和术语,这些概念和术语特定于该出版物中科学的新颖性。 例如,一篇期刊文章的介绍性部分可能会定义作者感兴趣的元背景——例如某种疾病的下一个突破性治疗方法——但文章的实际新颖性是一种评估化学过程的新分析方法。 像 CAS SciFinder 这样使用精选数据的解决方案将侧重于分析方法,而不是元上下文,以更好地响应用户的查询。
本体论将正确的想法与相关结果联系起来
我们建立这些联系的方式是通过本体,本体是精心策划的术语集合,包括捕获同义词关系。 这些关系提供了一个精致但仍然广泛的术语列表供利用。 如果用户通过商业名称搜索某种物质,我们的本体将包括化学名称、其他商业名称的变体,甚至在 专利申请中包含内部标识符。 如果没有这些连接,典型的搜索引擎就无法识别相关结果。
这就是为什么科学家为科学家构建的搜索工具可以推动更有效的创新——它们可以比优先考虑召回的搜索引擎更快地提供更相关的结果,并且数据可以捕获关键术语之间的层次关系。
例如,在 CAS SciFinder 中搜索术语 Sonic Hedgehog 与在普通搜索引擎中搜索 Sonic Hedgehog 会产生明显不同的结果。 CAS SciFinder 立即将其识别为蛋白质,并返回相关的科学出版物(见图 3)。 然而,一个通用的搜索引擎会返回众所周知的视频游戏角色,而不是科学家会寻求的蛋白质信息。
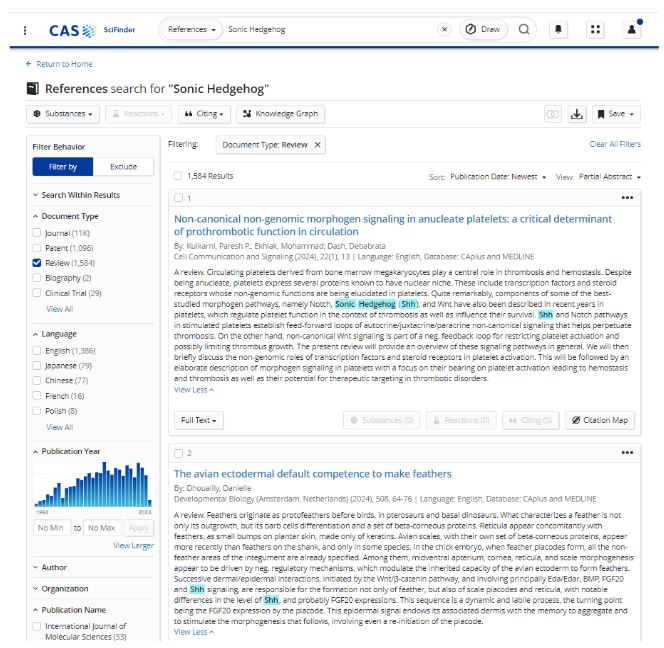
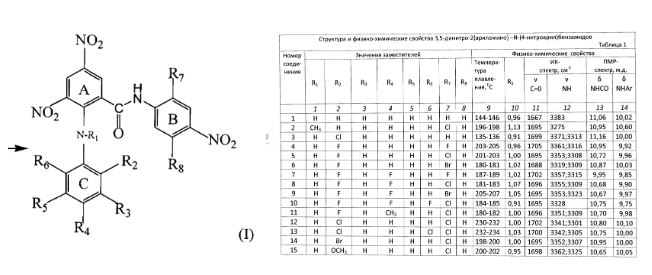
除了本体之外,人工策划的索引还可以进一步发现算法通常失败的地方。 人类可以识别代码和化学结构之间的联系,并建立定义化学实体的关系,而非人类策划的索引方法可能会遗漏这些关系。 这样就可以在图表中捕获数据,例如分子和化合物,并将该信息与可能位于出版物中其他位置的表格、图形或文本中的解释联系起来(参见图 4)。
如果没有策展,典型的搜索引擎必须依赖光学字符识别 (OCR) 来处理图形和图表,而像图像分辨率差这样简单的事情可能会导致错过重要的发现。 人工策划的解决方案,例如来自 CAS 团队的解决方案,充分利用了人类的最佳专业知识以及尖端技术的速度和算法进步。
数据质量对搜索的未来至关重要
科学搜索不像查找当地餐馆的评论,学术和商业机构都从平衡召回率和准确性的解决方案中受益。 随着任何科学领域的知识体系的增长,搜索能力也需要不断发展。 随着人工智能驱动的工具成为标准搜索解决方案,这一点只会变得更加重要。 大型语言模型 (LLM) 可能会在科学搜索方面 遇到困难 ,除非它们使用适当的数据进行训练,并且具有处理非文本数据的神经网络层。
凭借专家的策展、强大的本体论以及利用非文本数据的能力,专业解决方案可以应对不断完善和改进科学搜索和创新发现的挑战。




