

Resumo executivo
No cenário da pesquisa científica moderna, a inteligência artificial (IA) surgiu como uma força transformadora, alterando fundamentalmente a forma como os pesquisadores conceituam, conduzem e validam seu trabalho. A convergência da capacidade de computação, dos algoritmos avançados e dos vastos conjuntos de dados levou a IA da possibilidade teórica à necessidade prática em todas as disciplinas científicas.
Essa revolução aborda vários desafios de longa data que limitaram o progresso científico: o volume avassalador de dados gerados em campos como genômica, medicina e ciência dos materiais; o tempo e os custos extensos de processos como a descoberta de medicamentos; e as limitações cognitivas na geração de hipóteses. A IA oferece novos e promissores caminhos para superar esses desafios e encontrar descobertas importantes em muitas disciplinas científicas.
Por exemplo, nas ciências biomédicas, a IA revolucionou a previsão de estruturas de proteínas, acelerou o processo de descoberta de medicamentos e possibilitou a medicina personalizada. Da mesma forma, nas ciências dos materiais, a IA está acelerando a descoberta de novos materiais. Esses avanços abriram caminho para laboratórios autônomos e estruturas de design inverso que estão mudando o próprio método científico. A IA também avançou consideravelmente na otimização de processos possibilitando o ajuste experimental em tempo real para melhorar o rendimento e a eficiência, reduzindo o desperdício e os custos.
Realizamos uma análise quantitativa da Coleção de conteúdo do CASTM, o maior repositório de informações científicas com curadoria humana, para entender a implementação e o impacto desses avanços tecnológicos na descoberta científica. Analisamos sistematicamente mais de 310 mil artigos de periódicos e patentes da Coleção de conteúdo do CAS, abrangendo os anos de 2015 a 2025, empregando técnicas analíticas avançadas para identificar publicações relacionadas à IA e suas metodologias, instituições e domínios de pesquisa associados.
Nosso estudo explora a distribuição de métodos de IA em campos científicos com análises detalhadas de dois domínios críticos: ciências biomédicas e ciências dos materiais. Essas análises detalham conceitos dominantes, padrões de co-ocorrência de métodos de IA e classes de substâncias notáveis. Além disso, investigamos o papel da IA na otimização de processos industriais e aplicações emergentes.
Essas descobertas apresentam insights essenciais sobre o estado atual e a trajetória da integração da IA na pesquisa científica, oferecendo orientação valiosa para pesquisadores, instituições e formuladores de políticas na compreensão dos padrões de adoção tecnológica, na identificação de oportunidades de colaboração e na tomada de decisões estratégicas informadas sobre futuros investimentos em IA e direções de pesquisa.
O cenário dos modelos de IA na ciência
Para entender o contexto em que certos modelos são selecionados e seu impacto, conduzimos uma análise abrangente de publicações científicas, incluindo periódicos e famílias de patentes, que incorporaram métodos baseados em IA. A visualização de todo o cenário destaca a crescente integração dessas tecnologias entre as disciplinas científicas à medida que mais modelos e funcionalidades são desenvolvidos (ver Figura 1).
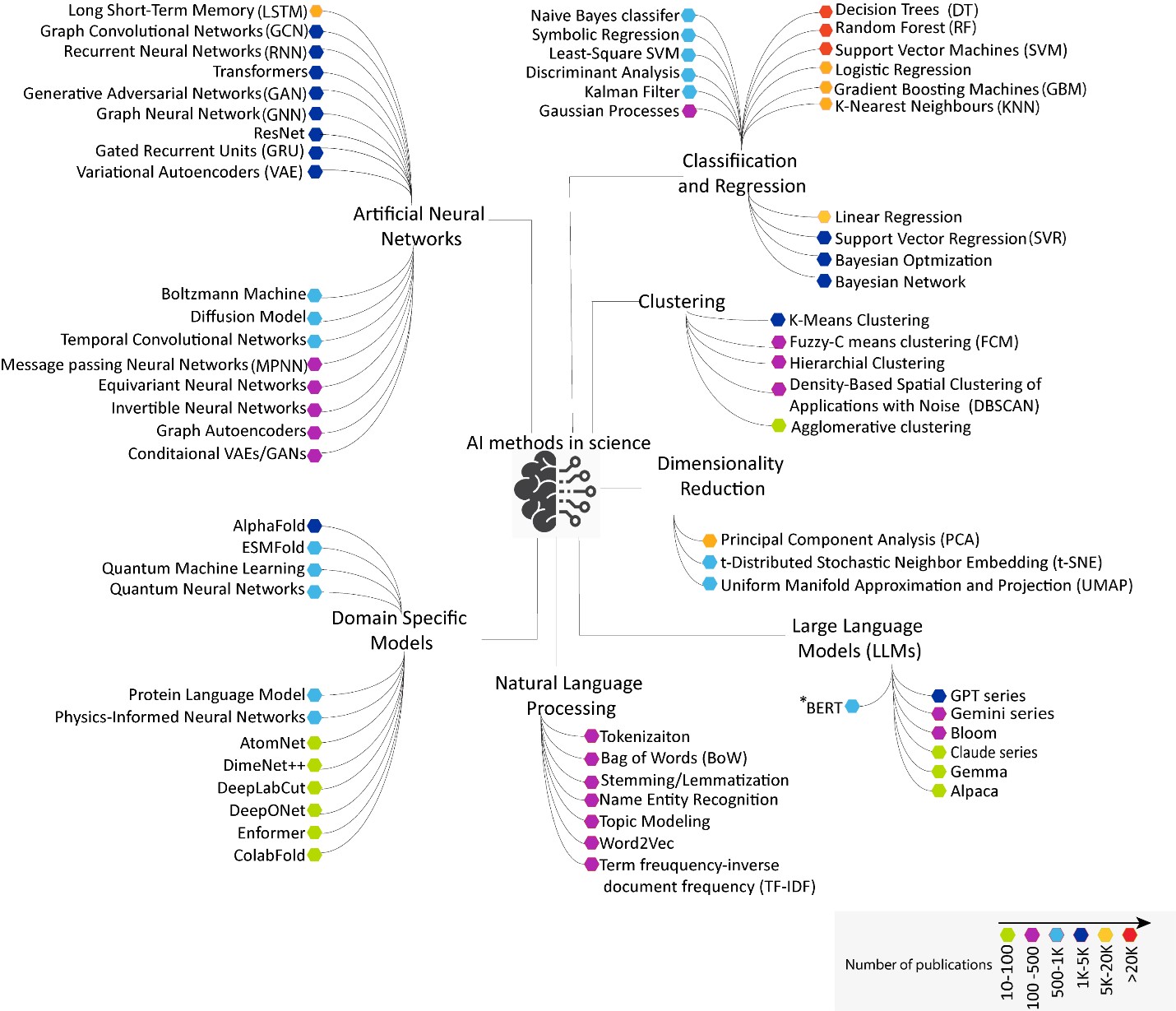
Os principais ramos desta visualização incluem:
Modelos de classificação, regressão e agrupamento
Os modelos de classificação foram projetados para prever rótulos ou categorias discretas e são especialmente eficazes no tratamento de dados de alta dimensão e na obtenção de resultados interpretáveis. Os modelos comuns são as Árvores de Decisão (Decision Trees, DT), um modelo que classifica os resultados dividindo recursivamente os dados em ramos. O Random Forest (RF) é um conjunto de árvores de decisão que reduz o overfitting por meio da média das previsões. Outro modelo comum, Support Vector Machine (SVM), encontra o limite ideal entre as classes, enquanto o K-Nearest Neighbors (KNN) classifica a classe majoritária dos vizinhos mais próximos.
Esses modelos são amplamente aplicados a conjuntos de dados rotulados (aprendizado supervisionado) com resultados categóricos, como espectroscopia, microscopia ou dados ômicos com classes conhecidas. Alguns exemplos de aplicações são a classificação de tipos de doenças a partir da expressão gênica ou de dados de imagem, a previsão de classes de materiais e a classificação de compostos com base na toxicidade ou reatividade.
Os modelos de regressão preveem valores numéricos contínuos, tornando-os ideais para previsão e otimização. Alguns dos modelos de regressão observados nas publicações são Regressão Linear, Regressão Logística, Regressão de Vetor de Suporte (SVR) e Regressão Simbólica. Esses modelos são adequados para dados numéricos de experimentos, simulações ou dados de séries temporais de sensores ou instrumentos. As aplicações incluem a previsão de níveis de energia, taxas de decaimento ou trajetórias de partículas, estimativa de rendimentos de reações, propriedades moleculares, modelagem de temperatura, precipitação, previsão de condutividade, dureza e intervalos de banda.
Diferentemente da classificação e da regressão, os modelos de agrupamento descobrem agrupamentos naturais em dados não rotulados, revelando estruturas ocultas e apoiando a análise exploratória (aprendizado não supervisionado). Esses modelos são eficazes para conjuntos de dados de alta dimensão e não rotulados, como dados de imagem, espectro e moleculares. Os dados científicos adequados para este grupo incluem, mas não se limitam a, o agrupamento de genes ou amostras com base em perfis de expressão e a descoberta de novas famílias de materiais a partir de dados estruturais.
Redes neurais artificiais (ANNs)
As ANNs são uma classe de modelos de aprendizado de máquina (ML) projetados para aprender padrões complexos através de camadas interconectadas de neurônios artificiais. São poderosos para modelar relações intrincadas e não lineares nos dados. Consequentemente formam a base para o deep learning e são o alicerce da IA moderna com arquiteturas especializadas, como as Redes Neurais Recorrentes (RNNs) para dados sequenciais, a Long-Short Term Memory (LSTM), uma RNN aprimorada que captura melhor as dependências de longo alcance e as Gated Recurrent Units (GRUs), versão simplificada das LSTMs com menos parâmetros.
Esses modelos são adequados para dados de sequência e séries temporais, como expressão gênica, sequências de proteína, sinais fisiológicos, dados climáticos, física de partículas e dados de redes de sensores. Muitas vezes, eles aprimoram o alinhamento entre imagem e texto pelo aproveitamento de mapas de Conhecimento — representações estruturadas de conceitos específicos do domínio e seus relacionamentos — o que ajuda a preencher a lacuna semântica entre dados visuais (como imagens médicas) e descrições textuais (como notas clínicas ou relatórios de diagnóstico). Sua adoção aumentou em áreas como descoberta e desenvolvimento de medicamentos, medicina de precisão, imagem médica, descoberta e design de materiais, armazenamento de energia, fabricação e controle de qualidade.
Métodos hibridizados
A comparação entre ANNs e modelos convencionais de ML, como classificação, regressão e agrupamento, não é simplesmente sobre qual é melhor, mas sim sobre a compreensão de suas funções complementares. As ANNs dominam onde os dados são complexos e não estruturados, onde há grandes conjuntos de dados de treinamento e quando o aprendizado de representação é necessário. Por outro lado, o ML convencional continua forte quando os dados são pequenos, os problemas de pesquisa exigem interpretabilidade rigorosa e as entradas possuem relações estatísticas bem compreendidas e exigem quantificação da incerteza.
Modelos específicos de domínio
Embora os modelos específicos de domínio tenham menos publicações, eles incluem trabalhos inovadores como o AlphaFold, abordagem de aprendizado profundo que alcançou precisão quase experimental na previsão da estrutura de proteínas. ESMFold é outro modelo interessante que aproveita diretamente a modelagem de linguagem de proteínas para gerar previsões de estrutura de alta qualidade diretamente de sequências de proteína únicas.
Processamento de Linguagem Natural (NLP)
A PLN é utilizada para analisar, compreender, interpretar e gerar linguagem humana. Envolve tarefas como a tokenização (dividir o texto em unidades menores chamadas tokens, geralmente palavras ou subpalavras) que podem ser processadas por algoritmos. Um método comum para representar texto é o modelo Bag of Words (BoW), que converte texto em vetores numéricos com base na frequência das palavras, ignorando a gramática e a ordem das palavras. Outra técnica importante é o Reconhecimento de Entidades Nomeadas (NER), que identifica e classifica entidades como nomes de pessoas, organizações e locais no texto.
Há amplas aplicações de modelos de PLN na mineração de textos biomédicos e na extração de conhecimento, que vão desde modelos de linguagem especializados treinados previamente na literatura biomédica (ou seja, BioBERT, BioGPT) e análise de registros eletrônicos de saúde (EHR) até a extração automática de características de doenças de registros clínicos e a criação de novos candidatos a medicamentos usando modelos de linguagem. Na ciência dos materiais e na química, a PLN tem sido utilizada para extração de protocolos de síntese, previsão de propriedades de materiais, construção de bases de conhecimento e design inverso.
Grandes modelos de linguagem (LLMs)
Essa classe transformadora de sistemas de IA revolucionou o PLN e encontrou amplas aplicações em domínios científicos. Os LLMs são sistemas baseados em redes neurais que são treinados em vastas quantidades de dados de texto para aprender padrões estatísticos de linguagem. São usados em extração de informações, resumo, construção de grafos de conhecimento, integração entre domínios e aplicações generativas.
Os LLMs amplamente adotados são o Generative Pre-Trained Transformer (GPT), do ChatGPT, GPT-3.5 e GPT-4. O Bidirectional Encoder Representations from Transformers (BERT) continua sendo um dos principais modelos de linguagem, mantendo grande interesse acadêmico devido à sua compreensão do contexto bidirecional e ao desempenho superior na resposta a perguntas e na análise de sentimentos.
O BLOOM, modelo multilíngue, surgiu como uma contribuição significativa para o cenário de pesquisa. Novos modelos, como o GEMINI, desenvolvido pelo Google DeepMind, e o LLAMA, da Meta AI, também estão se tornando populares, assim como o Claude, desenvolvido pela Anthropic. Os modelos de última geração Gemma, Falcon, Mistral, Qwen e DeepSeek, lançados entre 2023 e 2025, mostram grande promessa para desenvolvimentos futuros.
Vários LLMs especializados em química, ciências da vida e ciência dos materiais também estão causando impacto, como chemLLM, PharmaGPT e MatSciBERT.
Tendências de publicação mostram o impacto da IA na ciência
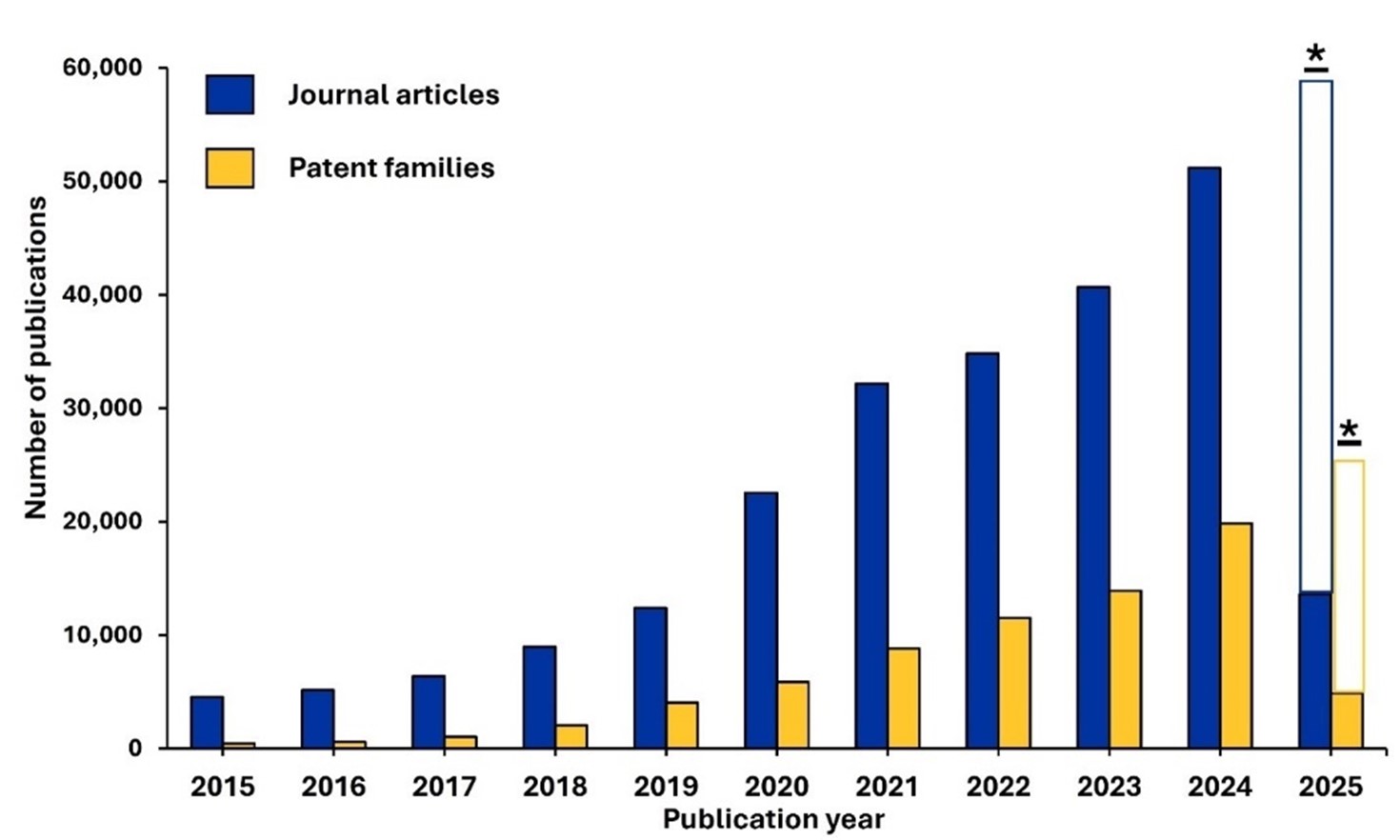
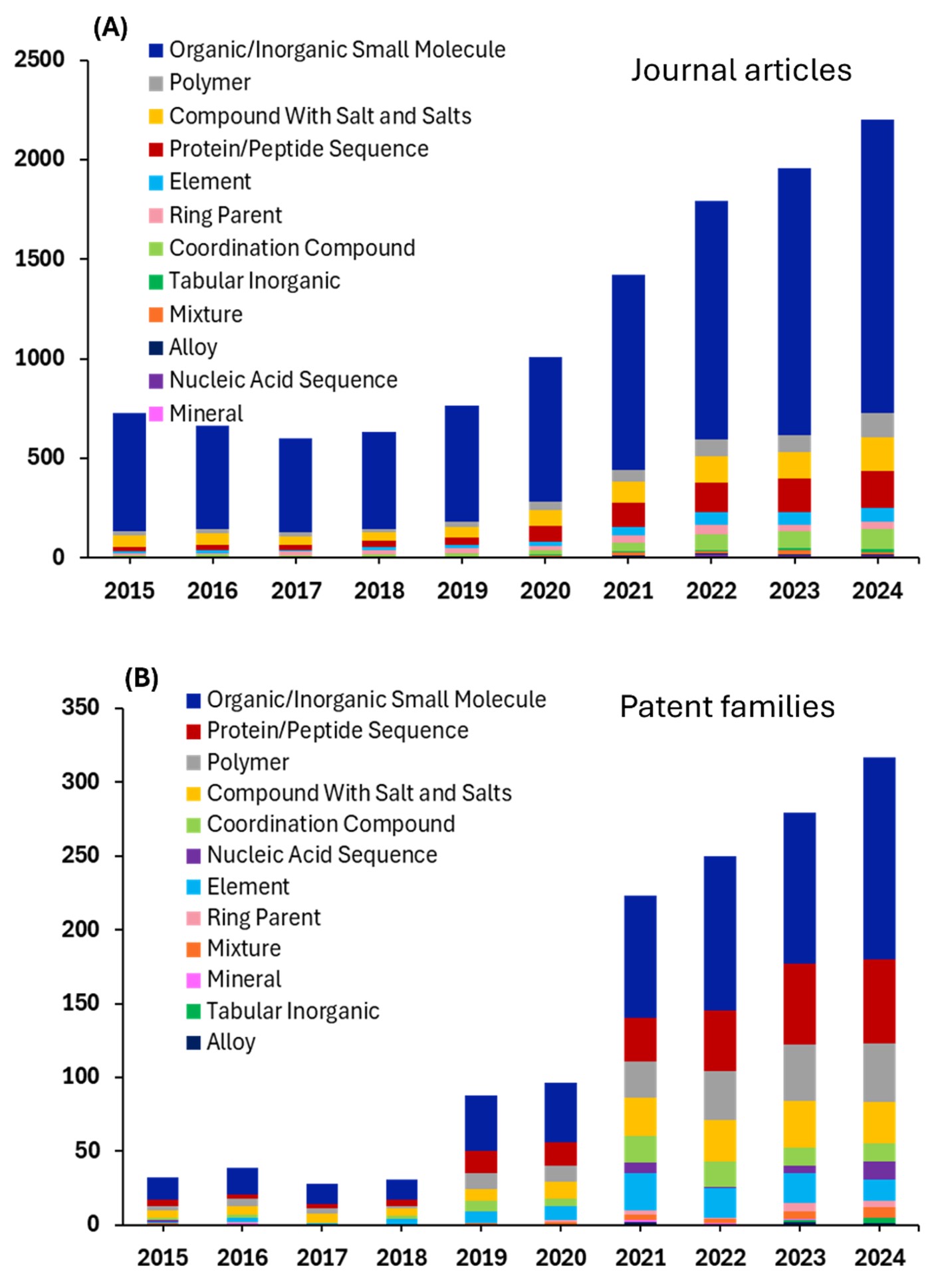
Conforme observado, analisamos 310.000 documentos na Coleção de Conteúdo do CAS relacionados à IA em pesquisas científicas no período de 2015-2025. Observamos um crescimento constante ao longo de todo o período, com crescimento proeminente nos últimos cinco anos (ver Figura 2). O número crescente de famílias de patentes sugere ainda que a IA está evoluindo de uma tecnologia emergente para uma ferramenta de pesquisa essencial em vários setores.
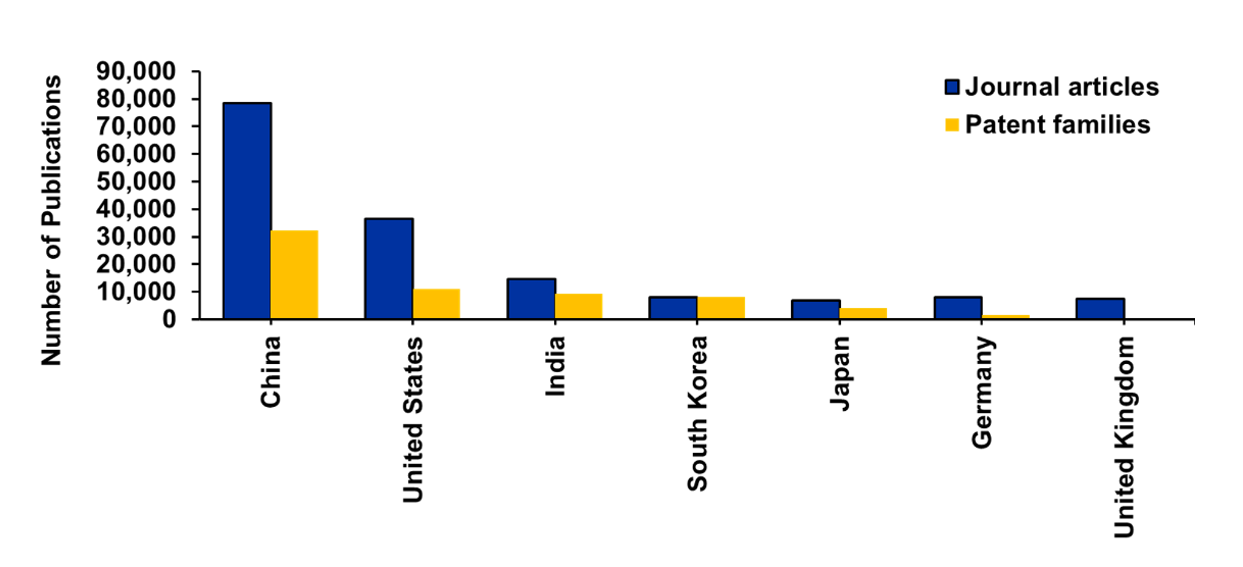
- Distribuição por país/região e organização: A China lidera em volume de publicações (periódicos e patentes), enquanto os EUA, a Índia, a Coreia do Sul e o Japão também mostram um crescimento constante nas publicações (veja a Figura 3). Em termos de patentes, China e Índia juntas contribuem com mais de 75% das patentes globais nesse campo — as 15 principais instituições em termos de registros de patentes são da China e da Índia. As universidades chinesas dominam em termos de volume de publicações, com a contagem média de citações para a maioria delas variando entre 10 e 20. Por outro lado, MIT e Stanford apresentam uma média de citações consideravelmente maior, de 32 e 66, respectivamente. Isso sugere que, embora a China se sobressaia em quantidade, as universidades dos EUA estão na liderança em termos de qualidade e impacto de seus artigos de periódicos no campo da IA.
- Distribuição em publicações científicas específicas: Analisamos o volume de publicações e o impacto das citações dos principais periódicos que publicam pesquisas baseadas em IA. O volume de publicações é dominado por Scientific Reports, Applied Sciences e PLoS One. No entanto, considerando a contagem média de citações por artigo, o Proceedings of the National Academy of Sciences (PNAS) se destaca, demonstrando uma influência excepcional com quase 50 citações por publicação, apesar de ter um volume de publicação relativamente modesto. Outros Periódicos, como o Journal of Chemical Information and Modelling (JCIM), Bioinformatics e Nature Communications, também apresentam uma média de citação notável, superando consideravelmente os periódicos com grande volume. Esse padrão sugere que embora periódicos de escopo amplo como o Scientific Reports publiquem a maior parte da pesquisa relacionada à IA, os periódicos especializados ou de prestígio como PNAS, JCIM e Nature Communications, publicam trabalhos mais influentes que geram maior impacto científico.
- Tendências por área científica: Numerosos campos foram muito afetados pela IA, mas alguns se destacam pelo crescimento exponencial das publicações (veja a Figura 4):
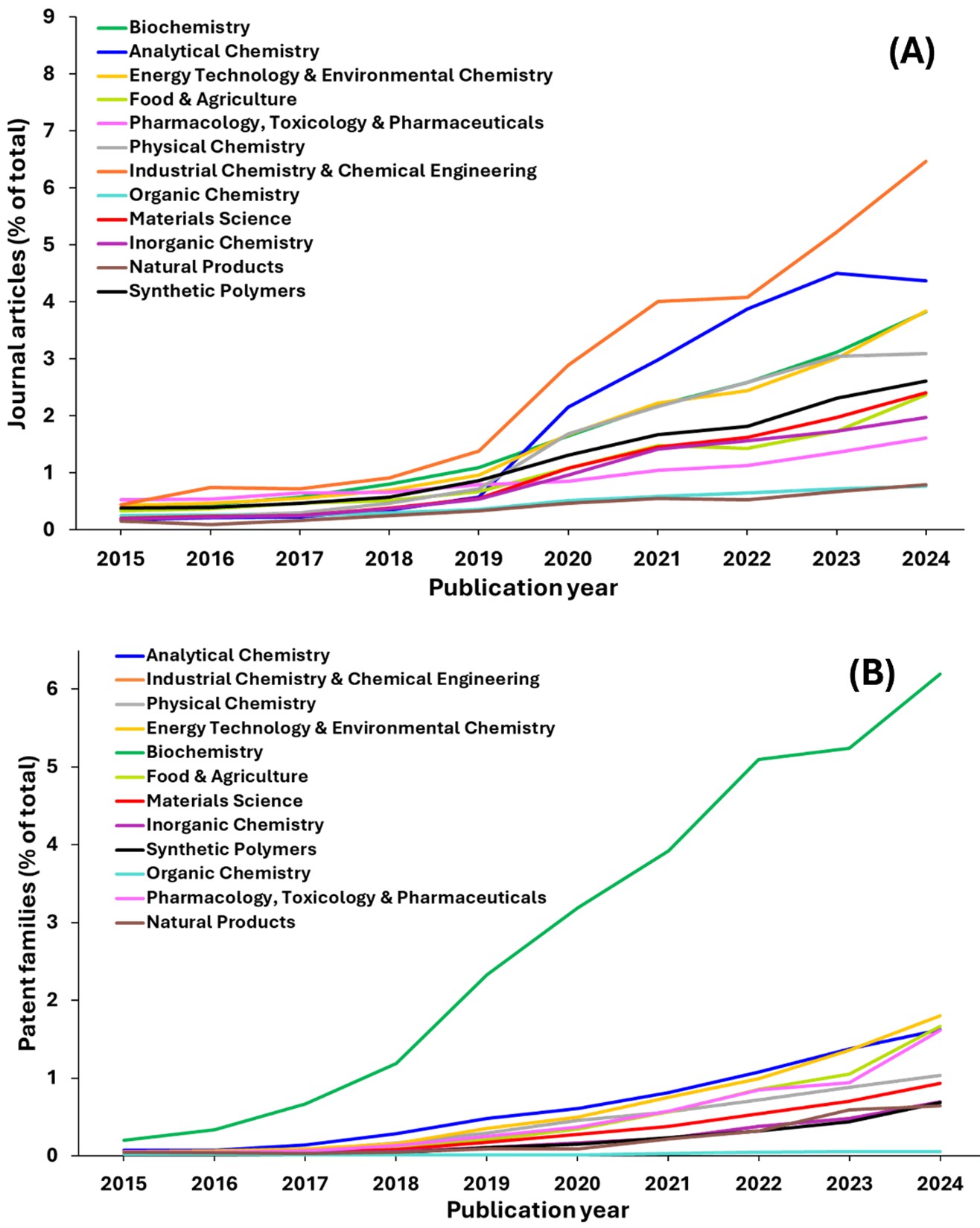
Entre todas as disciplinas, química industrial e engenharia química demonstram o crescimento mais expressivo em publicações em periódicos, com sua trajetória atingindo aproximadamente 8% do total de documentos até 2024. Esse crescimento excepcional provavelmente reflete as amplas aplicações do campo em manufatura, otimização de processos e inovação industrial, bem como seu papel essencial no desenvolvimento de processos industriais sustentáveis e soluções de química verde.
A química analítica surge como o segundo campo de crescimento mais rápido em termos de publicações em periódicos, com a linha azul escura mostrando um crescimento robusto ao longo do período de 2019 em diante. Esse forte padrão de crescimento mostra a importância fundamental do campo em todas as áreas da química e seu papel no desenvolvimento de novas técnicas de medição, instrumentação e métodos analíticos que dão apoio à pesquisa em várias disciplinas.
A tecnologia de energia e química ambiental demonstra um crescimento sólido, ocupando com o terceiro lugar entre os campos de crescimento mais rápido, assim como com a bioquímica. Isso reflete o foco global urgente nas mudanças climáticas, nos desafios de sustentabilidade ambiental e nos eventos emergentes.
As demais disciplinas, incluindo físico-química, farmacologia, toxicologia e produtos farmacêuticos, química orgânica, química inorgânica, produtos naturais e polímeros sintéticos, demonstram aumentos modestos, mas consistentes, no volume de publicações. Esses campos representam áreas maduras de pesquisa científica em que os princípios fundamentais estão bem estabelecidos, mas a investigação contínua produz avanços e refinamentos incrementais.
Os dados da família de patentes apresentam um cenário marcadamente diferente em comparação com as publicações em periódicos, com padrões de inovação altamente variados e concentrados, em vez do crescimento uniforme observado na produção acadêmica. Esse contraste destaca a diferença fundamental entre a produtividade da pesquisa acadêmica e a inovação comercialmente viável, onde as forças do mercado, as aplicações práticas e os incentivos econômicos desempenham papéis decisivos na determinação de quais avanços científicos se traduzem em propriedade intelectual patenteável.
Entre as patentes, a bioquímica apresenta um crescimento exponencial, atingindo aproximadamente 8% até 2024 e ofuscando completamente todas as outras disciplinas. O cenário de patentes de bioquímica é dominado por métodos biomédicos e moldado por Inovações que mesclam a ciência molecular com tecnologias avançadas de saúde. Os principais domínios são detecção de doenças, imagens médicas, monitoramento vestível e apoio a decisões clínicas, todos com aproveitamento de marcadores bioquímicos. A bioquímica também impulsiona o progresso em interfaces neurológicas, genômica, descoberta de biomarcadores, processamento de sinais, orientação cirúrgica e fabricação biomédica, destacando seu papel central na inovação biomédica moderna. Essa dramática atividade de patente reflete o intenso interesse comercial e o investimento em pesquisa em ciências da vida em geral e foi ainda mais impulsionada em resposta à pandemia de COVID, onde a pesquisa comercial recebeu financiamento significativo.
Com base em nossa análise, descobrimos que a maioria das publicações relacionadas à IA está relacionada à pesquisa biomédica e à ciência dos materiais. Por isso realizamos uma análise detalhada dessas principais áreas de pesquisa, pois esses campos dominam o conjunto de dados, apresentam rápida adoção de IA com taxas de crescimento anual notáveis e produzem impactos de citação mais altos, indicando sua relevância científica.
Aplicações de modelos de IA em pesquisa biomédica
Visão geral
A pesquisa biomédica tem enfrentado desafios constantes de complexidade e custos que a IA agora pode resolver. Por exemplo, a decodificação de estruturas e interações complexas de proteínas, os altos custos e as taxas de fracasso associadas ao desenvolvimento de medicamentos e as complexidades da compreensão dos mecanismos de doenças multifatoriais se prestam a abordagens baseadas em IA.
A justificativa por trás dessa análise era garantir uma amostragem representativa das áreas de pesquisa mais significativas, usando a frequência de documentos como uma métrica objetiva para identificar conceitos-chave. Especificamente, identificamos conceitos que geraram grande interesse científico e investimento em pesquisa usando vários métodos de IA/ML no campo biomédico (veja a Figura 5).
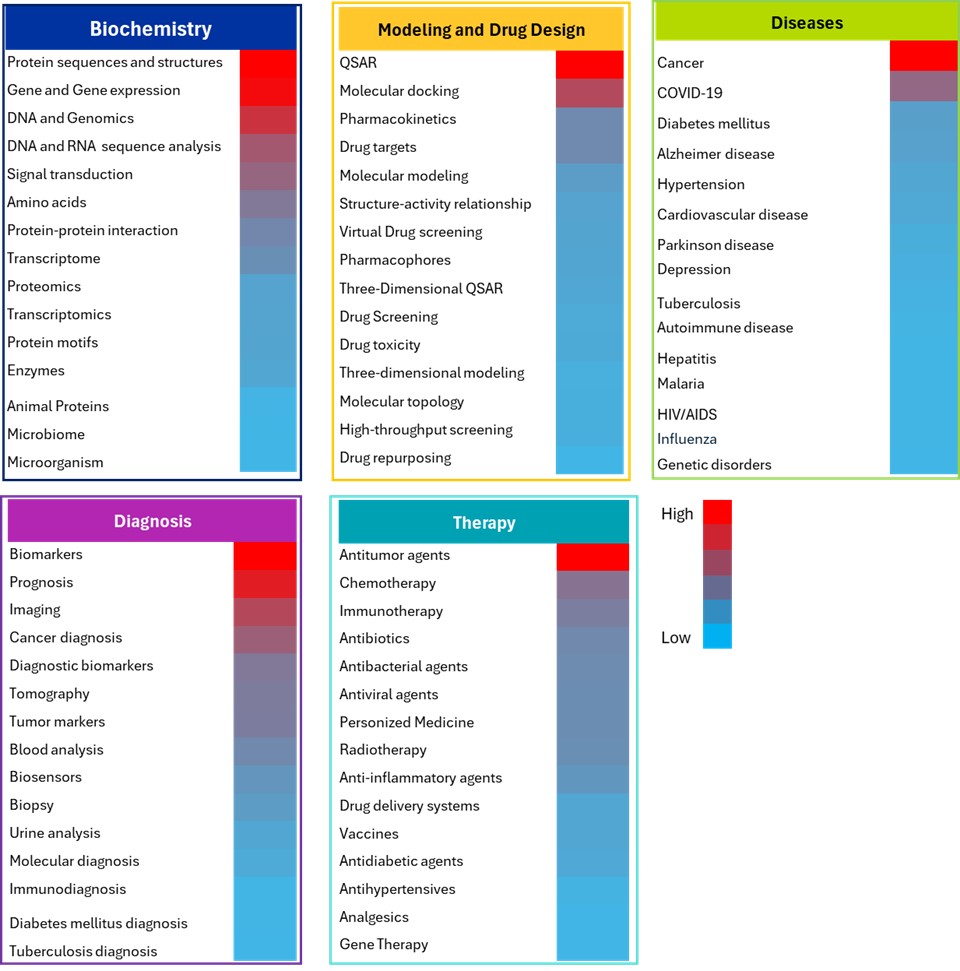
No domínio da bioquímica, sequências de proteínas e estruturas, genes e expressão gênica e DNA/genômica surgiram como os conceitos mais extensivamente estudados, utilizando diversas abordagens de aprendizado de máquina. Os modelos de ML prosperam nessas áreas devido à abundância e padronização de dados, especialmente em sistemas complexos como hierarquias de proteínas e redes regulatórias de genes. ML destaca-se em tarefas como mapeamento de função de sequência, classificação de famílias de proteínas, previsão de domínio, análise de estrutura-função, seleção de características tumorais, previsão de interação gênica no câncer e agrupamento de genes por expressão em padrões em oncologia, aproveitando dados de expressão de alta dimensão com milhares de genes medidos simultaneamente, relações não lineares complexas entre genes e fenótipos e organização hierárquica de redes regulatórias genéticas.
Modelos avançados de ML, como AlphaFold e BERT, são utilizados para a previsão da estrutura de proteínas, aprendendo com sequências de aminoácidos e padrões evolutivos para prever o dobramento 3D e os domínios funcionais. Esses modelos lidam de forma eficaz com relações espaciais complexas e entradas sequenciais com dependências de longo alcance.
No domínio de modelagem e design de medicamentos, a modelagem QSAR domina esse campo. Utiliza métodos de ML para extrair descritores moleculares (ou seja, propriedades físico-químicas, impressões digitais) de estruturas químicas para prever atividades biológicas e pontos finais de toxicidade por meio de abordagens de aprendizado supervisionado. Esses métodos são excelentes com descritores moleculares ricos em recursos, relações estrutura-atividade e pontos finais quantitativos adequados para tarefas de regressão.
O acoplamento molecular, o segundo conceito mais frequente, utiliza abordagens de aprendizado profundo (CNN e GNN) em dados estruturais 3D e gráficos moleculares para prever poses e afinidades de ligação proteína-ligante, utilizando conformações espaciais, cenários energéticos e interações moleculares. A farmacocinética é a próxima área de foco, utilizando ML para aprender com descritores moleculares, parâmetros fisiológicos e dados de séries temporais para prever propriedades ADMET (absorção, distribuição, metabolismo, excreção, toxicidade) e taxas de depuração de medicamentos.
Biomarcadores dominam o domínio de diagnóstico onde os métodos de ML analisam dados genômicos, proteômicos e metabolômicos de alta dimensão para identificar assinaturas moleculares discriminativas que distinguem estados de doença de controles saudáveis por meio de seleção de características e classificação. Os métodos de IA também são usados em pesquisa de prognóstico para analisar dados clínicos de pacientes e histórico de tratamento para prever tempos de sobrevivência e progressão da doença por meio de técnicas de análise de sobrevivência.
As imagens médicas contêm dados de raios-X, tomografia computadorizada (CT), ressonância magnética (MRI) e informações espaciais estruturadas, ideais para métodos de aprendizado profundo. As CNNs são amplamente utilizadas para analisar imagens radiológicas para detecção de tumores, identificação de fraturas, classificação de doenças e condições patológicas por meio do reconhecimento automático de padrões. A geração de imagens também pode se beneficiar da capacidade do aprendizado profundo de extrair características em várias escalas e realizar tarefas de segmentação, especialmente no diagnóstico de câncer, onde auxilia na detecção de tumores, classificação, avaliação de malignidade e previsão de riscos.
No domínio da doença, a pesquisa do câncer recebeu a maior atenção, com vários modelos de ML aplicados com base nos tipos de dados. Os dados genômicos e transcriptômicos são comumente analisados com modelos de RF e SVM para classificação de subtipos de câncer e previsão de tratamento. Essas tarefas se beneficiam da integração de dados multi-ômicos, que capturam diversas camadas moleculares, e da modelagem da complexidade de microambientes tumorais heterogêneos.
Vários algoritmos são utilizados na pesquisa sobre diabetes para prever complicações diabéticas e otimizar protocolos de tratamento, aproveitando dados de monitoramento longitudinal, interações complexas entre fatores de estilo de vida e genética, e problemas de previsão de séries temporais para os níveis de glicose. Na doença de Alzheimer, os modelos RF e SVM são amplamente utilizados para previsão precoce, analisando pontuações de testes neuropsicológicos, níveis de biomarcadores (proteínas amiloide-beta e tau) e dados demográficos para classificar pacientes em categorias saudáveis ou com comprometimento cognitivo leve.
No domínio da terapia, os agentes antitumorais receberam a maior atenção da pesquisa, empregando métodos de ML para triagem de medicamentos e previsão de atividade por meio da análise de descritores moleculares e propriedades químicas para identificar compostos com potencial atividade anticâncer. Na quimioterapia, esses métodos predizem as respostas ao tratamento e a toxicidade analisando dados clínicos do paciente, perfis genéticos e características do tumor para personalizar a seleção de medicamentos e os protocolos de dosagem. Da mesma forma, esses modelos apoiam a imunoterapia analisando os perfis imunológicos do paciente, a carga mutacional tumoral e as expressões de biomarcadores para prever a resposta e otimizar os resultados terapêuticos, abordando a complexidade das interações imunes e da dinâmica temporal.
Co-ocorrências de modelos de IA e conceitos biomédicos
Nossa análise explora os padrões de co-ocorrência entre conceitos biomédicos e vários métodos de IA/ML, elucidando suas aplicações estratégicas nos cinco domínios (veja a Figura 6).
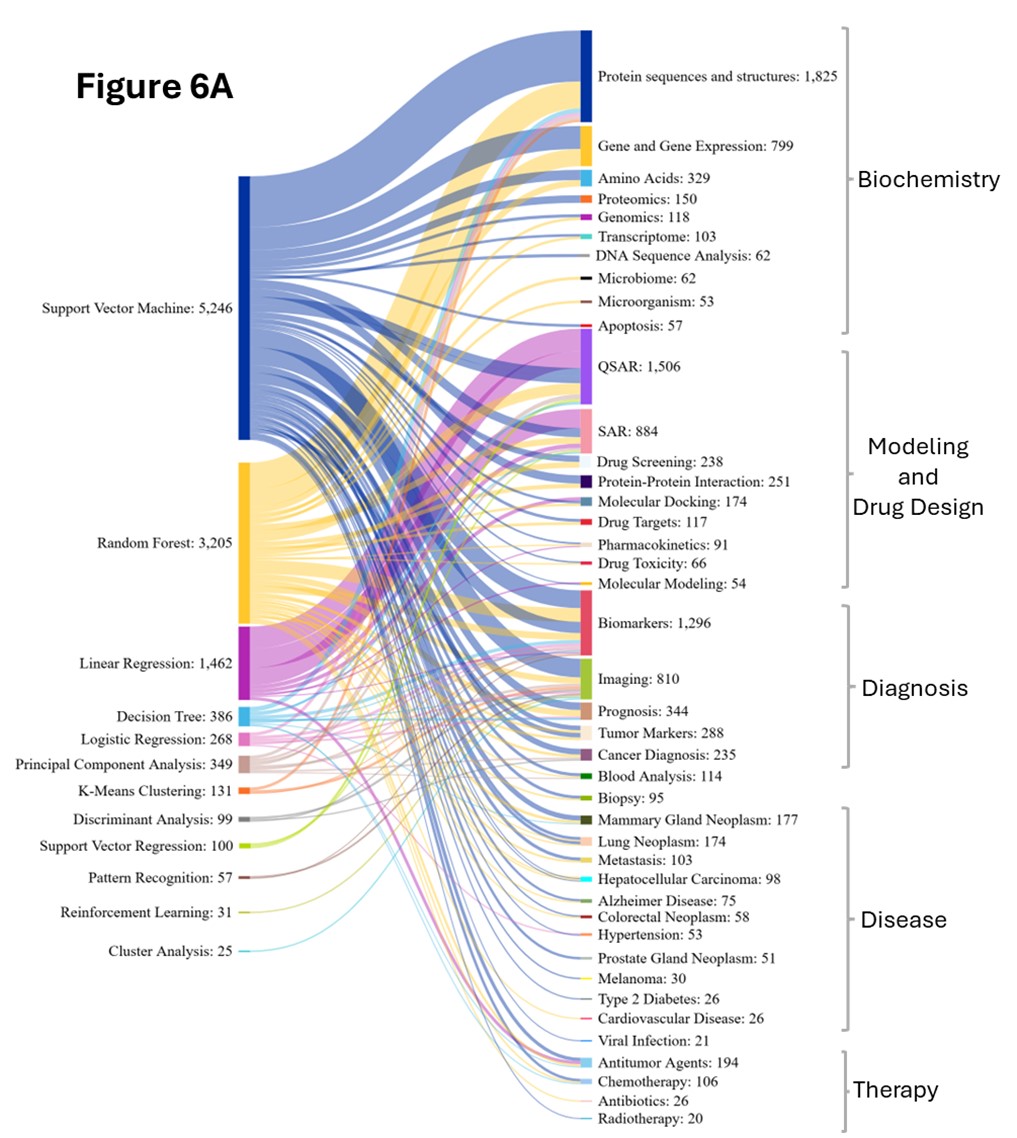

Random Forest (RF) surgiu como o método de IA dominante na pesquisa biomédica, mostrando um crescimento notável e superando a Máquina de Vetores de Suporte (SVM) entre os dois períodos. RF mostra forte co-ocorrência com conceitos em todos os domínios das ciências biomédicas, particularmente em bioquímica, diagnóstico e pesquisa relacionada a doenças. RF é usada para previsão e classificação da função proteica, analisando a composição de aminoácidos, motivos de sequência e propriedades físico-químicas para classificar proteínas em famílias funcionais. Na descoberta de biomarcadores, RF é usada para analisar dados genômicos, proteômicos e metabolômicos de alta dimensão.
Máquina de vetores de suporte (SVM) , embora cresça constantemente entre os períodos, mantém uma presença significativa com proteínas, expressão gênica, DNA e genômica, biomarcadores, prognóstico, imagens médicas e pesquisa sobre câncer. Em estudos de proteínas, o SVM é usado para classificação e anotação funcional de proteínas por meio da análise de sequências de aminoácidos, características estruturais e propriedades físico-químicas. Ele também prevê a localização subcelular e identifica classes de enzimas usando o mapeamento de espaço de recursos de alta dimensão baseado em kernel.
Na expressão gênica, o SVM identifica genes envolvidos em processos bioquímicos específicos, classifica vias metabólicas e prevê genes codificadores de enzimas com base em seus padrões de expressão em diferentes condições bioquímicas e estados celulares. Para a classificação de variantes genômicas, o SVM processa as características e as anotações da sequência de DNA para distinguir mutações patogênicas de benignas e identificar regiões genômicas associadas a doenças por meio da análise de características de alta dimensão dos padrões de nucleotídeos e do contexto genômico.
Na pesquisa de biomarcadores, o apoio do SVM à identificação, classificação e validação integra vários biomarcadores em modelos preditivos para diagnóstico, resposta ao tratamento, avaliação do risco de progressão da doença e estratificação de pacientes para abordagens de medicina personalizada. O SVM é usado em pesquisas sobre câncer para distinguir entre tecidos normais e cancerosos, classificar tipos de câncer e identificar subtipos moleculares dentro de cânceres específicos. Também é usado em prognósticos de câncer e previsão de tratamento, integrando parâmetros clínicos, perfis de biomarcadores e características genômicas para prever os resultados de sobrevivência do paciente, respostas ao tratamento, padrões de resistência a medicamentos e risco de recorrência. A Figura 6B revela que o SVM manteve a força na modelagem de QSAR e SAR, enquanto suas conexões com a análise de proteínas enfraqueceram em relação à RF no período posterior.
A regressão logística (LR) é um método estatístico interpretável e amplamente utilizado na pesquisa biomédica, frequentemente co-ocorrendo com conceitos-chave, como proteínas, expressão gênica, biomarcadores, prognóstico, imagens médicas, câncer e COVID-19. Na previsão da função da proteína, a LR analisa a composição de aminoácidos, as características de sequência e as propriedades estruturais para classificar as proteínas em categorias funcionais ou estruturais. A principal vantagem do modelo é apresentar coeficientes interpretáveis que indiquem a contribuição relativa de cada característica para a decisão de classificação, permitindo que os pesquisadores identifiquem quais propriedades de aminoácidos ou características estruturais influenciam mais fortemente as previsões.
Essa interpretabilidade é igualmente valiosa na classificação da expressão gênica, onde a LR ajuda a identificar genes diferencialmente expressos. Para validação de biomarcadores e diagnósticos, os modelos de LR preveem resultados binários, como doença/saúde ou respondedor/não respondedor, e apresentam razões de chances clinicamente importantes para a tomada de decisões de diagnóstico. Na modelagem de prognóstico, a LR usa uma previsão de resultado binário semelhante, avaliando parâmetros clínicos, perfis de biomarcadores e dados demográficos do paciente para prever resultados como mortalidade/sobrevivência, recorrência/remissão da doença, prognóstico favorável/desfavorável.
A LR é usada no diagnóstico, na previsão de gravidade e na mortalidade da COVID-19, integrando comorbidades, sinais vitais e biomarcadores, apoiando a estratificação de risco e a tomada de decisões clínicas. Essas diversas aplicações ressaltam o forte alinhamento da LR com os principais temas de pesquisa biomédica, tornando-a uma ferramenta fundamental para modelagem interpretável e clinicamente relevante. A Figura 6B ilustra a Aumentar adaptabilidade da regressão logística, provavelmente devido à capacidade de classificação multiclasse e resultados baseados em probabilidade, ao contrário da regressão linear, que se limita a previsões contínuas.
Como mostrado na Figura 6B, o período 2020-2024 testemunhou o surgimento de abordagens especializadas de aprendizado profundo pouco presentes anteriormente, como AlphaFold. Nesse período também houve um aumento no uso de Graph Neural Networks (GNN) em modelagem de interação molecular, Graph Adversarial Networks (GAN) para geração de dados sintéticos e Reconhecimento de Padrões para aplicações de imagem e desafios de diagnóstico.
Outra grande mudança nos últimos anos é a integração das técnicas de PLN na pesquisa biomédica, destacada pelo surgimento de modelos como o BERT para minerar relatórios clínicos e analisar textos biomédicos. Essa especialização reflete o amadurecimento do campo além da aplicação de métodos genéricos de IA, desenvolvendo abordagens personalizadas para desafios biomédicos específicos.
As prioridades de pesquisa mudaram substancialmente entre os dois períodos. A análise de sequências de proteína e estrutura e a análise de expressão gênica cresceram consideravelmente em 2020-2024 (Figura 6B). A descoberta de biomarcadores e as aplicações de imagem também experimentaram um crescimento dramático, enquanto a pesquisa específica de doenças se expandiu consideravelmente, com a COVID-19 emergindo como um foco importante e a pesquisa sobre o câncer se diversificando em vários subtipos.
Substâncias em pesquisa biomédica
Essa comparação apresenta insights estratégicos sobre oportunidades terapêuticas pouco exploradas e destaca classes de substâncias que podem se beneficiar do aumento do investimento em pesquisa ou abordagens inovadoras para preencher a lacuna entre a descoberta científica e a aplicação clínica (ver Figura 7). Observe que "classes de substâncias" se referem a categorias de substâncias indexadas pelo CAS com reconhecidas potenciais aplicações terapêuticas.
Os medicamentos de moléculas pequenas continuam dominando a pesquisa farmacêutica e o desenvolvimento, com as tecnologias de IA acelerando sua descoberta. A triagem virtual baseada em ML, a modelagem QSAR para previsão farmacocinética, e os sistemas de aprendizado profundo que otimizam as vias sintéticas agora são parte integrante desse processo. Essas inovações se baseiam nas vantagens inerentes às moléculas pequenas, incluindo rotas de síntese estabelecidas, farmacocinética bem caracterizada, biodisponibilidade oral e fabricação econômica.
Terapêuticos de proteínas/peptídeos constituem a segunda categoria mais pesquisada. Ferramentas como o AlphaFold revolucionaram a previsão da estrutura de proteínas, possibilitando o design e a otimização de proteínas terapêuticas, como insulina para diabetes, ativador de plasminogênio tecidual para derrames e anticorpos monoclonais para câncer e doenças autoimunes. Modelos de ML aprimoram ainda mais este campo, prevendo interações proteína-proteína e otimizando a estabilidade de peptídeos.
Compostos com sal e sais se beneficiam de algoritmos de otimização de formulação baseados em IA que predizem solubilidade, biodisponibilidade e estabilidade, refletindo a importância da formulação de medicamentos e da otimização da biodisponibilidade. Os polímeros, que muitas vezes servem como sistemas cruciais de entrega terapêutica, estão sendo aprimorados por meio de formulações de nanopartículas projetadas por IA, propriedades de hidrogel otimizadas por ML e modelagem preditiva para entrega de medicamentos direcionados, melhorando a eficácia terapêutica e a especificidade do tecido.
Os compostos de coordenação são outra classe promissora, onde a IA auxilia no design de ligantes e na otimização de estruturas metal-orgânicas (MOF). Esses compostos estão sendo refinados por meio de química computacional e modelos de IA que preveem interações metal-ligante e atividade biológica.
Aplicações de modelos de IA na ciência dos materiais
Visão geral
Em ciência dos materiais, conhecer e prever as relações complexas entre a composição do material, características estruturais e propriedades é essencial para acelerar a descoberta de materiais. Os dados envolvidos são frequentemente multidimensionais, hierárquicos, heterogêneos e gerados por meio de processos de alto rendimento e intensivos em dados. A IA, particularmente ML, está revolucionando o campo possibilitando a análise desses conjuntos de dados complexos. Analisamos a Coleção de conteúdo do CAS para identificar os principais conceitos de ciência de materiais onde os métodos de IA são aplicados e avaliamos sua importância na descoberta de materiais e previsão de Propriedade (ver Figura 8).
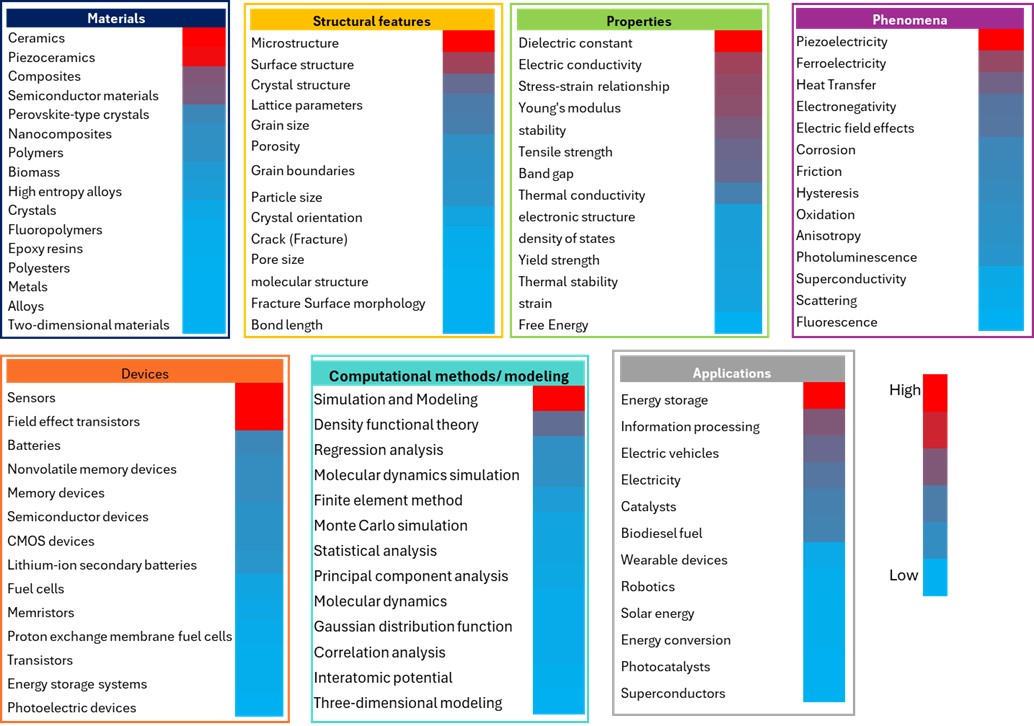
O armazenamento de energia é a área de pesquisa mais intensiva em IA em aplicações, refletindo a necessidade global por tecnologias avançadas de baterias e soluções de energia sustentável. As técnicas de AM se tornaram ferramentas potentes para a inovação de materiais de baterias, com os pesquisadores utilizando três estratégias principais: previsões diretas de propriedades, potenciais de aprendizado de máquina e design inverso. A alta concentração de pesquisas de IA nesse campo decorre da natureza complexa e em várias escalas dos sistemas de baterias, onde as abordagens experimentais tradicionais muitas vezes não conseguem otimizar as intrincadas relações entre a composição do material, a estrutura e o desempenho eletroquímico.
Nas categorias Materiais e Dispositivos, a significativa atividade de IA em cerâmica, piezocerâmica, sensores e transistores de efeito de campo reflete a natureza sofisticada desses materiais e de seus dispositivos. Esses materiais avançados geralmente apresentam relações complexas entre estrutura e propriedade, que são candidatos ideais para abordagens de ML.
Em características estruturais, descobrimos que as redes neurais convolucionais (CNNs) junto com a visão computacional são usadas para análise microestrutural, permitindo classificação automática, segmentação e extração de características de imagens de microscopia. Essas ferramentas estão ajudando a encontrar relações estrutura-propriedade que antes eram difíceis de quantificar. Na metalurgia, as abordagens de IA direcionadas estão avançando no desenvolvimento de superligas, enquanto sistemas como o CAMEO (Closed-Loop Autonomous Materials Exploration and Optimization) permitem a metalurgia combinatória integrando IA com experimentação de alto rendimento. Além disso, as ferramentas de aprendizado de máquina para dados de tomografia 3D estão aprimorando a análise de materiais porosos, permitindo uma modelagem mais precisa de propriedades como permeabilidade e resistência mecânica.
A constante dielétrica e a condutividade elétrica são os principais conceitos em Propriedades, enquanto a piezoeletricidade lidera em Fenômenos. Em Simulação e Modelagem, a modelagem computacional mostra uma alta adoção da IA, o que se alinha à compatibilidade natural do aprendizado de máquina com as tarefas de análise de dados.
As áreas de atividade moderada de IA, representadas pelas regiões roxas e de cores mistas na Figura 7, são campos onde a adoção da IA está se acelerando, mas ainda há espaço para melhorias. Por exemplo, a baixa atividade em algumas áreas de materiais, predominantemente mostradas em azul, representa alguns dos domínios mais estabelecidos e fundamentais da ciência, criando uma situação paradoxal em que os campos mais maduros apresentam a menor integração de IA. Os materiais compostos e os polímeros são exemplos principais dessa categoria.
No entanto, estão sendo desenvolvidos modelos especializados de IA para enfrentar desafios específicos. O modelo polyBERT trata as estruturas de polímeros como uma linguagem química, permitindo uma modelagem mais eficaz de sistemas complexos de polímeros. Para materiais cristalinos, modelos como MEGNet, CGCNN e SchNet incorporam a simetria cristalina e as interações quânticas, enquanto o ALIGNN captura interações atômicas de ordem superior, essenciais para a previsão precisa de propriedades de ligas.
Co-ocorrências de modelos de IA e conceitos de ciência de materiais
Assim como em nossa análise biomédica, observamos atentamente os métodos de IA e os conceitos coincidentes na ciência dos materiais. Descobrimos que modelos tradicionais de ML, como Random Forest (RF), Support Vector Machine (SVM), Gradient Boosting Machines (GBM) e Decision Trees (DT), são amplamente usados para previsão e análise de importância de características, em grande parte devido aos dados de alta dimensão com relações não lineares que são comuns na informática de materiais (ver a Figura 9).
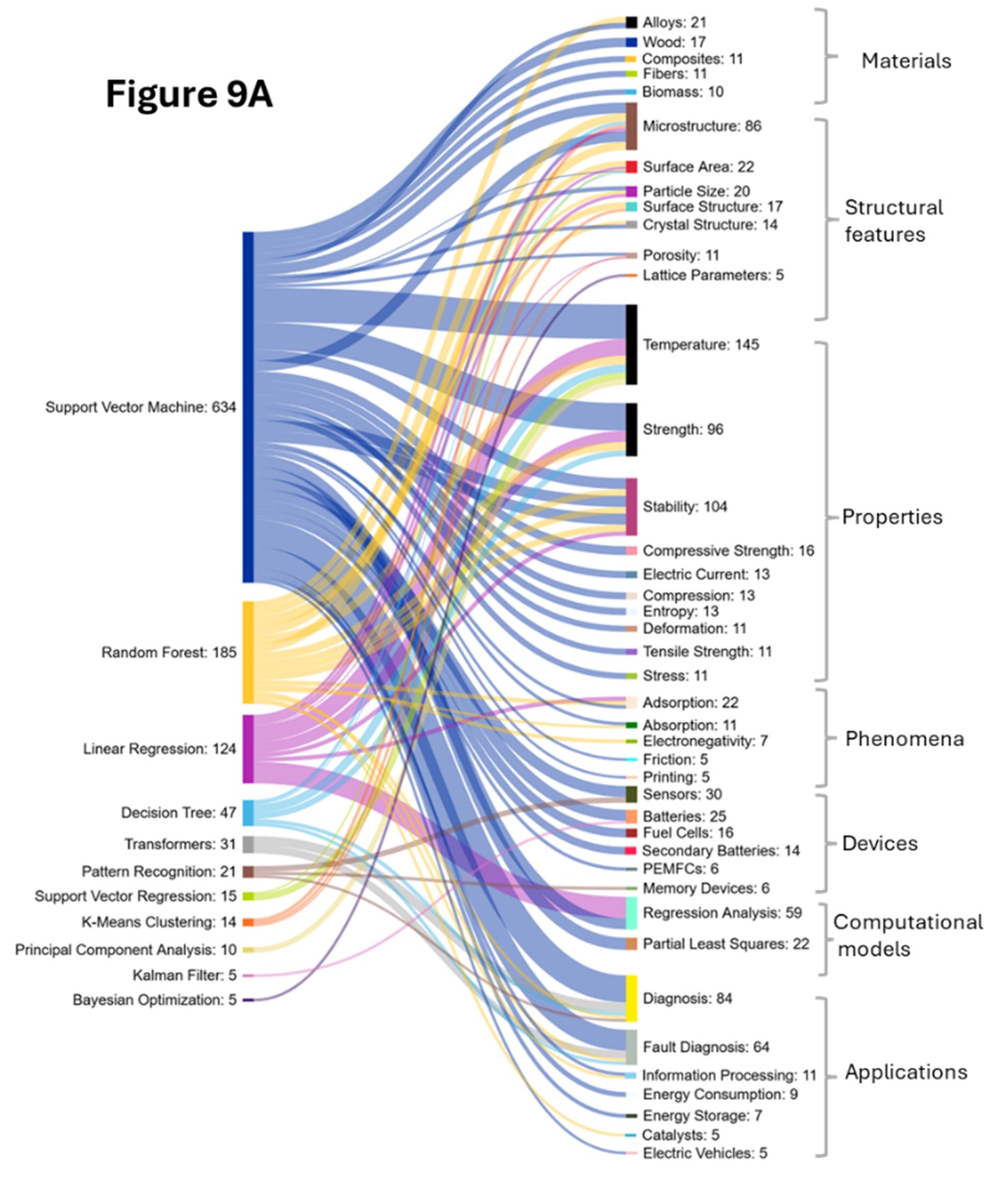
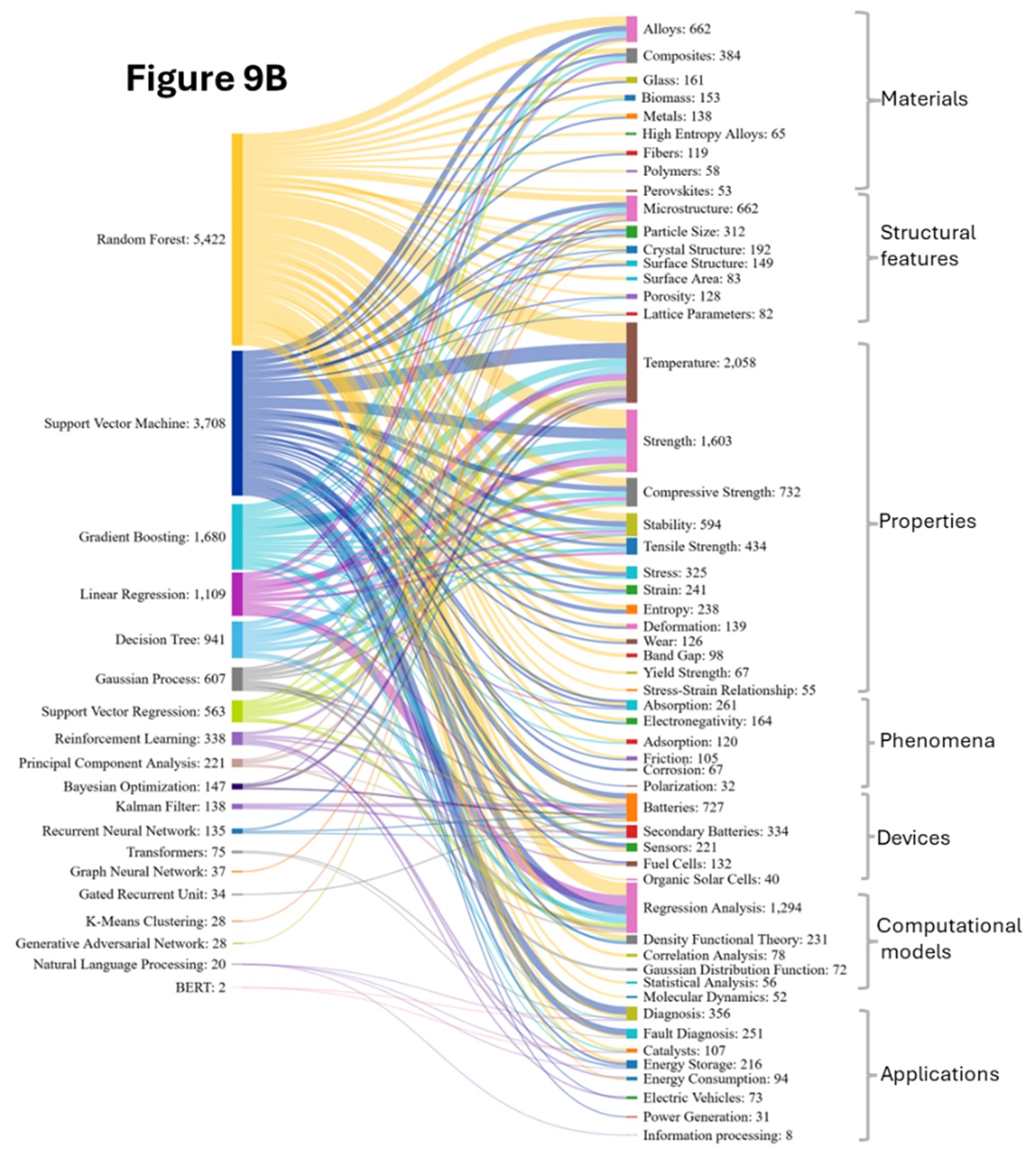
Os Modelos de RF são amplamente utilizados e distribuídos em todas as áreas conceituais. Junto com modelos GBM, apresentam fortes co-ocorrências com materiais complexos e heterogêneos devido à sua capacidade de modelar relações não lineares e lidar com tipos de dados mistos. São frequentemente utilizados para compósitos heterogêneos, previsão de propriedades mecânicas e análise de falhas, capturando as complexas interações entre matriz e reforço.
Vemos isso ocorrendo com ligas, onde a RF é usada para mapear relações não lineares em composições de ligas, auxiliando no projeto de ligas de alta entropia, previsão de fortalecimento de precipitação e otimização do tratamento térmico. A GB é cada vez mais aplicada para o ajuste preciso de propriedades, como a otimização da resistência ao escoamento ou da resistência à corrosão.
SVM é mais frequentemente usado com materiais com relações bem definidas entre estrutura e propriedade. Esse tipo de modelo é eficaz para classificar tipos de ligas e limiares usando vetores de características de dimensão fixa. As propriedades dependentes da temperatura também costumam seguir padrões não lineares e dependem da composição, do histórico de processamento e das condições ambientais, que os métodos baseados em árvores e os SVMs capturam com eficiência.
Para características estruturais, como microestrutura, modelos de conjunto são empregados para identificar características de imagens complexas; classificar limites de grãos, fases e defeitos; e prever estruturas cristalinas, muitas vezes tratadas como problemas de classificação que exigem modelos sensíveis à simetria. As propriedades de superfície, que abrangem escalas atômicas a macroscópicas, envolvem padrões complexos de energia e reatividade de superfície. Essas aplicações exigem o pré-processamento de dados de imagem, a extração de características em várias escalas e a codificação de simetria e periodicidade, especialmente para estudos de catálise, corrosão e adesão, muitas vezes exigindo a integração com a modelagem molecular.
Os domínios de aplicação se expandiram consideravelmente, com a pesquisa sobre baterias apresentando crescimento dramático. As Figuras 9A e 9B confirmam a forte correlação da RF com os processos eletroquímicos, lidando com interações complexas para a previsão da capacidade da bateria, a seleção do material do eletrodo e os processos dependentes do tempo.
O surgimento de aplicações relacionadas à energia (armazenamento de energia, geração de energia) no período de 2020 a 2024 demonstra a diversificação do campo. A LSTM (Long-Short Term Memory) captura as dinâmicas temporais cruciais para a previsão da degradação da bateria e do desempenho do ciclo. Outra correlação emergente é o Reinforcement Learning (RL), capaz de otimizar os protocolos de carregamento e o uso de materiais e pode ser usado em sistemas de gerenciamento de baterias. Os filtros de Kalman também são observados com baterias e baterias secundárias utilizadas para rastrear o estado do material durante o processamento e prever a estimativa do estado de saúde da bateria e a previsão da vida útil restante.
São utilizados transformadores na extração de procedimentos de síntese e propriedades de materiais da literatura científica e na captura de dependências de longo alcance em descrições complexas de materiais. As redes neurais convolucionais (CNNs) e GANs automatizam a extração de recursos de estruturas 2D/3D e apoiam à previsão de propriedades e ao reconhecimento de padrões. Apesar de seu poder, exigem mais dados e computação e oferecem menor interpretabilidade, complementando, portanto, em vez de substituírem modelos tradicionais. As NNs são cada vez mais usadas na análise baseada em imagens e no design generativo, enquanto métodos tradicionais mantêm vantagens no mapeamento de propriedades de composição com conjuntos de dados limitados. Esse é outro motivo pelo qual redes neurais e modelos tradicionais são usados em conjunto. Outro desenvolvimento são arquiteturas de CNN específicas para materiais que incorporam simetria e restrições físicas, enquanto as GNNs estão ganhando força para estruturas atômicas e moleculares.
Substâncias na ciência dos materiais
Voltando às categorias de substâncias indexadas ao CAS, analisamos o número de publicações relacionadas a essas substâncias na Ciência dos materiais (ver Figura 10).
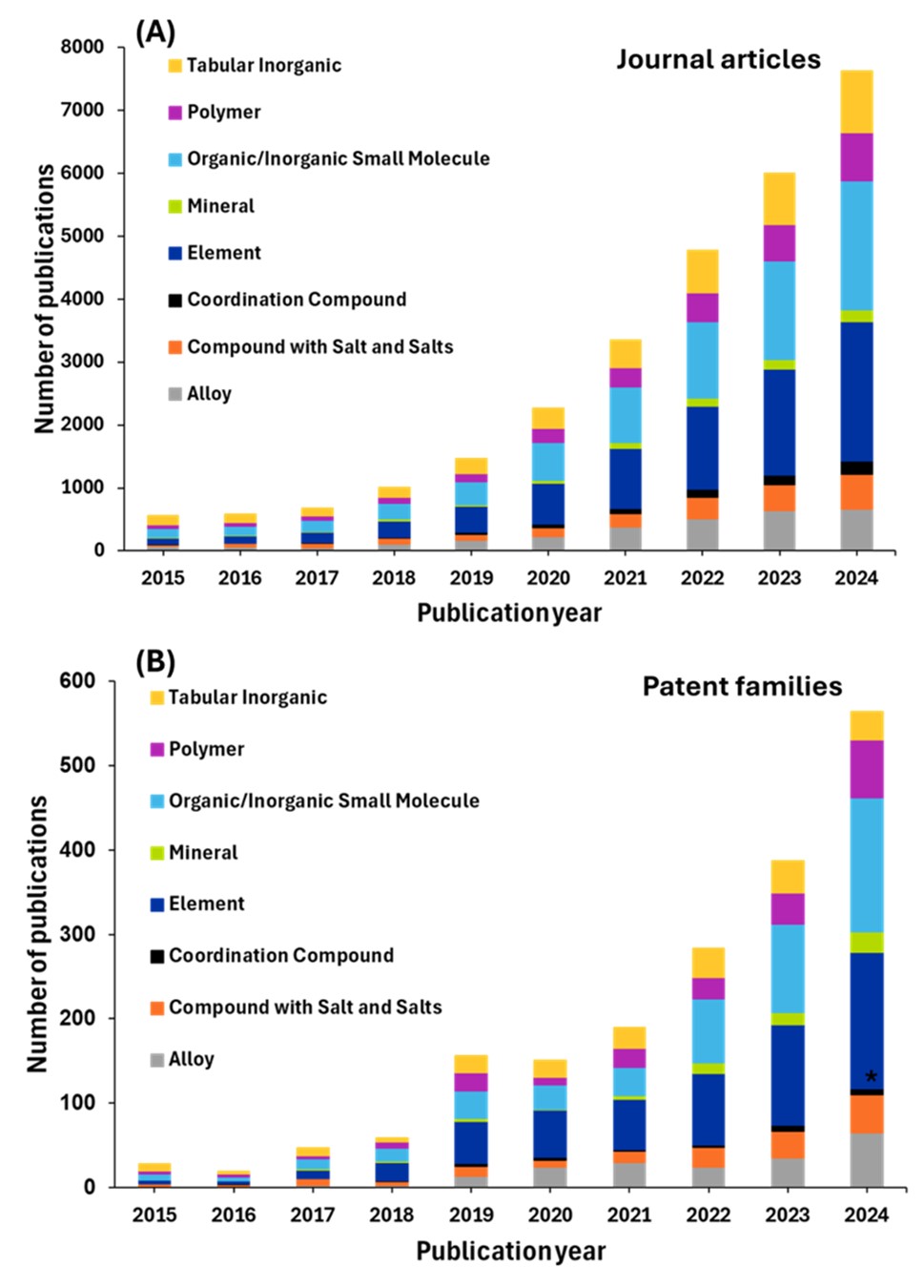
O domínio de pequenas moléculas orgânicas/inorgânicas na pesquisa conduzida por IA reflete as vantagens computacionais do campo e a abundância de dados no tratamento de pequenas estruturas em termos de custo computacional versus sistemas complexos maiores, como polímeros. Com aproximadamente 6.500 artigos de periódico, essa categoria se beneficia de décadas de bancos de dados químicos acumulados.
As moléculas pequenas são particularmente adequadas às abordagens de ML porque suas propriedades podem ser codificadas com eficiência usando descritores moleculares, impressões digitais e representações baseadas em grafos. O alto volume de pesquisa nessa área também indica o forte investimento dos setores farmacêutico e químico em IA para descoberta de medicamentos, design de catalisadores e previsão de propriedades moleculares.
Os elementos, ocupando o segundo lugar com cerca de 5.500 artigos, também se beneficiam de extensos bancos de dados e da relativa simplicidade de suas estruturas, tornando-os candidatos ideais para previsão de propriedades e descoberta de materiais orientadas por IA.
Os materiais inorgânicos tabulares, com aproximadamente 4.500 artigos de periódicos, representam outra área em que a IA encontrou aplicações substanciais. Esses materiais — que incluem cerâmicas, óxidos e outros compostos inorgânicos estruturados — se beneficiam de bancos de dados cristalográficos e medições sistemáticas de propriedades que fornecem os grandes conjuntos de dados necessários para um aprendizado de máquina eficaz. A natureza estruturada desses materiais possibilita a engenharia consistente de recursos com base na estrutura cristalina, na composição e nas características de ligação. O destaque dessa categoria na pesquisa de IA provavelmente reflete o foco da comunidade de ciência de materiais na descoberta de novos materiais funcionais para armazenamento de energia, catálise e aplicações eletrônicas e magnéticas.
As pesquisas sobre polímeros mostram uma adoção moderada da IA com cerca de 1.800 artigos de periódicos, o que pode parecer baixo, dada a importância industrial dos polímeros. Isso provavelmente reflete os desafios exclusivos que os polímeros apresentam para as aplicações de IA, incluindo suas estruturas de cadeia complexas, distribuições de massa molecular e propriedades dependentes do processamento. No entanto, o crescente volume de pesquisas sugere um sucesso crescente na aplicação da IA à previsão, síntese e otimização de processamento de propriedades de polímeros.
Outra descoberta importante da nossa análise é como as famílias de patentes representam apenas uma fração dos artigos de periódicos em todas as categorias de ciências dos materiais. A disparidade entre o número de periódicos e patentes sugere que grande parte da pesquisa em ciência dos materiais permanece no estágio fundamental ou exploratório, com atrasos consideráveis de tempo entre descobertas acadêmicas e aplicações práticas dignas de proteção de patente no estágio comercial.
O número relativamente pequeno de patentes também pode refletir o desafio de traduzir as descobertas de materiais baseados em IA em tecnologias comercialmente viáveis, já que muitas aplicações de IA nesse campo se concentram na previsão de Propriedade e na compreensão fundamental, em vez de invenções imediatamente patenteáveis. A proporção coerente entre os diferentes tipos de materiais indica que o desafio da aplicação acadêmica na área comercial é universal em toda a ciência dos materiais, não sendo específica de determinadas classes de materiais.
IA na gestão de processos
A IA está transformando o gerenciamento de processos possibilitando uma tomada de decisão mais inteligente, rápida e adaptável. A análise do papel da IA nesse domínio revela como a automação, a análise preditiva e a otimização em tempo real podem impulsionar a excelência operacional em todos os setores (veja a Figura 11).
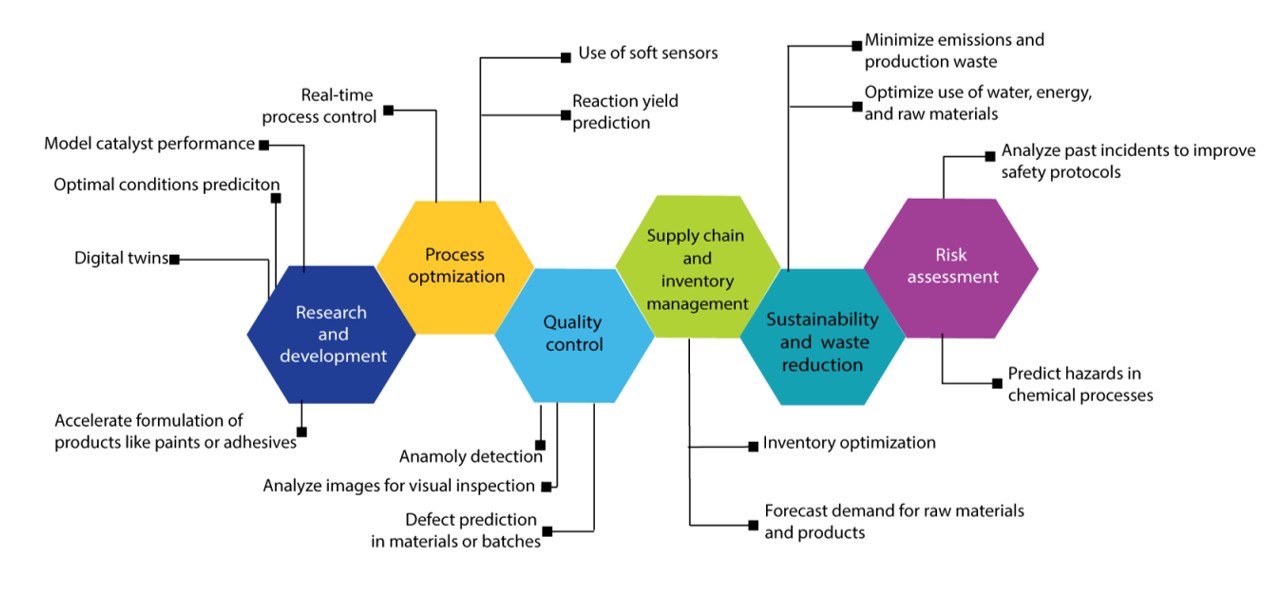
A otimização baseada em IA é amplamente utilizada em manufatura aditiva, indústrias petroquímicas, processamento de plásticos, metalurgia, química de fluxo, processos catalíticos e descoberta e síntese de fármacos. Os modelos comumente utilizados incluem a metodologia de superfície de resposta (RSM), o planejamento de experimentos e técnicas de ML, como ANNs, modelos híbridos, PINN, LLMs e abordagens de aprendizado por reforço. Vamos explorar algumas outras tecnologias que estão ampliando a modelagem preditiva para a tomada de decisões e automação em tempo real:
- Monitoramento em tempo real: esses sistemas analisam dados de streaming usando ML para detectar padrões, tendências e sinais de alerta precoce, facilitando a previsão dinâmica e a tomada de decisões proativa. As principais inovações incluem a tomada de decisão autônoma, em que os parâmetros são ajustados automaticamente com base em informações em tempo real; a manutenção preditiva que antecipa as falhas antes que elas ocorram; e modelos de autoaperfeiçoamento que se ajustam às condições variáveis. Além disso, a consulta de dados em tempo real e os sistemas de alerta inteligentes estão transformando a forma como os operadores interagem com os dados de processo em tempo real. Esses avanços estão sendo aplicados em vários setores, como sistemas de cromatografia automáticos e monitoramento de reações a medicamentos na fabricação de produtos farmacêuticos. Também estamos vendo seu uso na otimização de propriedade na produção de polímeros, análise de resíduos sólidos no gerenciamento de resíduos, monitoramento ambiental, gerenciamento de energia e recursos para produção de hidrogênio em grande escala e gerenciamento de energia baseado em nuvem para infraestruturas antigas.
- Sensores suaves: usando dados em tempo real de sensores físicos, eles utilizam modelos de IA e estatísticos para estimar variáveis difíceis ou caras de medir diretamente. São amplamente aplicados em vários setores, incluindo monitoramento de bioprocessos e monitoramento de águas residuais e qualidade do ar. No controle de processos químicos, sensores suaves são usados para monitorar a flutuação de minério de sulfeto complexo, isomerização, destilação reativa e mistura de gasolina.
- Gêmeos digitais: essas inovações são réplicas virtuais de sistemas físicos que estão evoluindo rapidamente com a integração da IA para permitir otimização em tempo real, análise preditiva e operações autônomas. A IA aprimora os gêmeos digitais aprendendo com dados históricos e em tempo real para simular estados futuros, detectar anomalias e prever falhas, transformando-os de modelos estáticos em sistemas resilientes e auto-otimizáveis. Na manufatura, gêmeos digitais baseados em IA preveem falhas nos equipamentos, otimizam processos de produção e detectam problemas de qualidade usando sensores e imagens. No setor de saúde, eles simulam condições do paciente, dão apoio a medicamentos personalizados, modelam doenças, simulam testes clínicos e otimizam a imunoterapia. Nos domínios ambiental e de sustentabilidade, gêmeos digitais com tecnologia de IA são aplicados no armazenamento geológico de carbono, no processamento de resíduos de minério e no gerenciamento de recursos. Eles também dão apoio à ciência dos materiais, permitindo a descoberta automática, a análise de defeitos e o design molecular inverso.
Desafios para o uso da IA na pesquisa científica
A IA claramente fez muitas contribuições positivas para todos os campos de pesquisa científica e continuará a fazê-lo à medida que avança. No entanto, essas inovações não estão isentas de desafios que pesquisadores e cientistas de dados devem enfrentar para garantir que a IA alcance seu pleno potencial na ciência. Alguns dos desafios mais urgentes incluem:
- Privacidade e segurança de dados: Garantir a privacidade e a segurança dos dados é um dos maiores desafios na implementação da IA, pois ela precisa de um grande volume de dados confidenciais para treinamento e operação. Os problemas ocorrem quando informações confidenciais são coletadas e usadas sem a devida permissão, ou quando informações confidenciais são vazadas ou roubadas de sistemas de IA. Os conjuntos de dados científicos podem conter resultados experimentais não publicados, novas estruturas de compostos e métodos de síntese proprietários que representam vantagens competitivas significativas. Quando os pesquisadores utilizam plataformas de IA baseadas em nuvem ou participam de ambientes de pesquisa colaborativa, enfrentam riscos substanciais de exposição à propriedade intelectual. Para combater o risco, algumas empresas estão implementando salvaguardas para proteger as informações dos clientes e manter a confiança, com novas startups encontrando nichos de mercado para se proteger contra ameaças externas de IA.
- Qualidade e viés dos dados: os conjuntos de dados frequentemente sofrem de vieses sistemáticos que podem se propagar por meio de modelos de IA, levando a previsões distorcidas e potencialmente reforçando as desigualdades de pesquisa existentes. Os vieses históricos nos dados publicados de reações, em que as reações bem-sucedidas são super-representadas e os experimentos fracassados são subnotificados, podem prejudicar consideravelmente a capacidade dos modelos de ML de explorar novos espaços químicos, principalmente para materiais inorgânicos. Esse "viés de publicação" cria um ciclo de autorreforço em que os sistemas de IA recomendam preferencialmente compostos semelhantes aos já bem estudados. Os modelos de IA generativa apresentam preocupações adicionais, pois podem manipular os dados existentes e alucinar para atender às solicitações dos clientes em detrimento de evidências reais.
- Transparência: A natureza "caixa preta" desses modelos pode obscurecer o raciocínio por trás de suas previsões, tornando difícil para os pesquisadores avaliar sua confiabilidade ou identificar possíveis modos de falha. Uma revisão dos métodos explicáveis de IA na descoberta de medicamentos destacou como a falta de interpretabilidade em modelos complexos pode minar a confiança entre os produtos químicos medicinais e impedir a aceitação regulatória de decisões guiadas por IA no desenvolvimento farmacêutico. Essa dificuldade é particularmente séria para redes neurais gráficas e modelos de transformadores que operam em representações químicas de alta dimensão, onde a relação entre as características de entrada e as previsões ficam altamente não-lineares.
- Equilíbrio entre automação e experiência humana: embora os sistemas de IA possam processar vastos conjuntos de dados e identificar padrões além da capacidade cognitiva humana, eles não têm a intuição, a criatividade e a compreensão contextual que cientistas experientes trazem aos problemas de pesquisa. Isso pode levar a uma geração de cientistas sem habilidades fundamentais de pesquisa e compreensão conceitual. Por outro lado, também pode levar à “aversão algorítmica” quando as conclusões baseadas na IA contradisserem a intuição.
Modelos de IA e o futuro da pesquisa científica
A IA só vai aumentar em importância para a investigação científica e suas capacidades revolucionárias já estão sendo percebidas em campos como biomedicina e ciência dos materiais. Como nossa análise da Coleção de Conteúdo do CAS mostra, há novas aplicações, modelos e métodos sendo aplicados a questões de pesquisa difíceis o tempo todo. Podemos esperar descobertas importantes na descoberta de medicamentos, diagnóstico de doenças, desenvolvimento de materiais e muito mais para serem influenciados ou totalmente impulsionados por tecnologias baseadas em IA.
À medida que a IA passa de ferramenta a parceira científica colaborativa, também é provável que vejamos novos paradigmas, como o design inverso e os laboratórios autônomos, redefinindo a metodologia científica em direção a mecanismos de descoberta autônomos. No entanto, a baixa relação entre patentes e publicações indica que muitas pesquisas permanecem na academia, principalmente nos campos tradicionais da ciência dos materiais.
A maior adoção da IA exige uma calibração adequada da confiança por meio de soluções técnicas como a quantificação da incerteza e a transparência do modelo. A natureza abrangente do impacto da IA na ciência e o escopo dos desafios de sua implementação significam que a colaboração e a visibilidade serão fundamentais para maximizar seus benefícios para o avanço científico.
Para obter mais informações, leia a nova edição impressa do nosso artigo de revista "A Revolução da IA na química: moldando o futuro dos materiais e das ciências biomédicas."
O uso de nomes de marcas e/ou de qualquer menção a produtos ou serviços de terceiros aqui contidos tem como objetivo exclusivamente fins educacionais e não implica em endosso do CAS ou da Sociedade Americana de Química, nem discriminação contra marcas, produtos ou serviços semelhantes não mencionados




