


La visión artificial, un campo de la inteligencia artificial (IA), permite a los ordenadores «ver» e interpretar el mundo visual como lo hacen los humanos. La visión por ordenador es mucho más que reconocer imágenes e implica comprender el contexto, las relaciones y los patrones en los datos visuales. Esto se consigue mediante sofisticados algoritmos y técnicas de aprendizaje profundo, como las redes neuronales convolucionales (CNN) y los transformadores de visión (ViT).
Estas herramientas extraen información significativa de las entradas visuales al transformar los datos en bruto de los píxeles en una comprensión semántica de alto nivel. Desde los coches autónomos y el control de calidad industrial hasta las imágenes médicas e incluso los filtros de las redes sociales, la visión artificial está revolucionando todo tipo de industrias y aspectos de la vida diaria. En la investigación científica, ya está logrando avances transformadores en numerosas disciplinas, y a medida que los conjuntos de datos crecen y la tecnología evoluciona, impulsará aún más avances.
Por qué la visión artificial es importante para la investigación científica
¿En qué se diferencia la visión por ordenador del aprendizaje automático (ML) y otros subgrupos de la IA/ML, y por qué es importante para la ciencia? Simplemente, esta tecnología permite a los científicos descubrir información valiosa rápidamente a partir de una vasta gama de datos visuales. En las últimas décadas, hemos visto una explosión de datos científicos, desde terabytes de datos astronómicos hasta millones de imágenes microscópicas, secuencias genómicas completas y mucho más. El volumen de datos es a menudo imposible de analizar manualmente, y gran parte de ellos se basa en imágenes, no en texto.
Esta es una diferencia crucial entre la visión por ordenador y otros subcampos dentro de la inteligencia artificial. Cuando el procesamiento del lenguaje natural (PNL) analiza los datos textuales secuenciales para buscar bibliografía y extraer conocimiento, la visión artificial gestiona los datos espaciales de alta dimensión y permite el análisis directo de las observaciones experimentales, las imágenes microscópicas y las lecturas de los sensores, donde las relaciones espaciales y los patrones visuales contienen la información científica básica.
Además, los métodos de ML tradicionales, como la regresión, la agrupación y la clasificación, utilizan conjuntos de datos preprocesados y creados a partir de características, mientras que la visión por ordenador moderna de aprendizaje profundo realiza un aprendizaje integral a partir de píxeles en bruto, extrayendo automáticamente características que correspondan y jerarquías espaciales que pueden no ser evidentes para los investigadores humanos. Esta distinción es fundamental en los contextos científicos, ya que pone de manifiesto las limitaciones de los modelos tradicionales de aprendizaje automático y las capacidades superiores de los modelos de aprendizaje profundo, especialmente para datos visuales complejos. Los modelos tradicionales de aprendizaje automático suelen estancarse en rendimiento cuando se enfrentan a conjuntos de datos complejos y no estructurados, y pueden tener dificultades para captar las diferencias visuales matizadas que sí pueden hacer los modelos de aprendizaje profundo.
Otro método habitual de la IA es el modelado predictivo, que prevé resultados basándose en datos anteriores. La visión por ordenador, por otro lado, descubre patrones y estructuras directamente a partir de observaciones visuales en bruto, revelando a menudo fenómenos no reconocidos previamente sin necesidad de hipótesis predefinidas o características de entrada estructuradas.
| Enfoque de IA | Tipo de datos principal | Diferencias clave |
|---|---|---|
| Visión artificial (CV) | Imágenes, vídeo, datos visuales y espaciales | Procesa datos a partir de píxeles en bruto; extrae automáticamente características y jerarquías espaciales; puede analizar información visual multiescala (de molecular a astronómica); permite el análisis directo de observaciones y lecturas de sensores. |
| Procesamiento del lenguaje natural (NLP) | Texto, datos secuenciales del idioma | Se centra en los patrones lingüísticos, la sintaxis y la semántica; se utiliza para la minería de bibliografía y la extracción de conocimiento de fuentes escritas. |
| Aprendizaje automático | Conjuntos de datos diseñados con ingeniería de características | Requiere datos preprocesados en lugar de entradas brutas; funciona con conjuntos de datos específicos; se basa en características definidas por el ser humano en lugar de en la extracción automática de características. |
| Modelización predictiva | Datos históricos/de series temporales | Predice los resultados futuros en función de los patrones del pasado; requiere hipótesis predefinidas y entradas estructuradas; proyecta las tendencias en lugar de descubrir patrones. |
Estas innovaciones analizan vastos conjuntos de datos mucho más rápido que los humanos. Esto se traduce en un análisis más rápido de posibles compuestos farmacológicos, un control de calidad más preciso en alimentos y productos industriales, e intervenciones más tempranas en la salud de los cultivos, por nombrar solo algunas aplicaciones. La visión por ordenador abre nuevas posibilidades para obtener conocimientos y avances en conjuntos de datos cada vez mayores, y facilita la supervisión automatizada 24 horas al día, 7 días a la semana, y la retroalimentación experimental en tiempo real en todas las disciplinas.
Casos de uso de la visión artificial en las ciencias
Si bien el núcleo de la tecnología de visión artificial, principalmente las CNN y los mecanismos de atención, sigue siendo similar en todos los campos científicos, su implementación varía según el tipo de datos visuales que se analicen y los objetivos científicos que correspondan. Por ejemplo, analizar anomalías sutiles en tejidos en escaneos médicos requiere un entrenamiento de modelos diferente al procesamiento de datos satelitales que rastrean índices de salud de las plantas a lo largo del espectro visual. Cada dominio requiere un preprocesamiento especializado, estrategias de entrenamiento y métricas de evaluación adaptadas a desafíos específicos de cada dominio (ya sea detectar eventos raros, medir cantidades precisas o interpretar relaciones espaciales complejas), aprovechando al mismo tiempo las mismas arquitecturas subyacentes de visión por ordenador.
- Investigación farmacéutica: el examen de las estructuras microscópicas, como moléculas y proteínas, es fundamental para el descubrimiento farmacéutico. La visión por ordenador es ideal para estas aplicaciones porque aplica estructuras de IA como las CNN y el ViT a estos conjuntos de datos visuales especializados. En el análisis de estructuras moleculares, la visión por ordenador agiliza el proceso de determinación de estructuras cristalográficas mediante la interpretación de patrones de difracción de rayos X y mapas de densidad electrónica. También identifica estructuras químicas a partir de datos espectroscópicos y dibujos moleculares.
Para el plegamiento de proteínas y la biología estructural, la IA analiza imágenes de criomicroscopía electrónica para reconstruir estructuras proteicas de alta resolución, valida predicciones de plegamiento computacional como AlphaFold y observa cambios conformacionales dinámicos que ocurren durante los procesos biológicos. En histopatología, la visión artificial facilita la detección automática del cáncer y la gradación de los tumores a partir de muestras de tejido, realiza análisis cuantitativos de las características celulares y los biomarcadores y procesa con precisión imágenes de diapositivas completas en gigapíxeles, superando a menudo a los patólogos humanos en precisión.
Las aplicaciones de cribado de fármacos emplean análisis de alto contenido para clasificar automáticamente las respuestas celulares a los tratamientos, supervisar la dinámica de las células vivas en tiempo real y evaluar modelos complejos de organoides 3D para comprobar la eficacia de los fármacos. Estas numerosas aplicaciones en el descubrimiento de fármacos muestran lo versátil que puede ser la visión por ordenador como herramienta científica, ya que agiliza el descubrimiento en todo el espectro de molecular a tisular de la investigación biomédica.
- Ciencia de los materiales: al igual que los productos farmacéuticos, la ciencia de los materiales exige analizar moléculas microscópicas para garantizar la consistencia del material, detectar defectos y confirmar que los pequeños cristales del interior de los metales y otros materiales están diseñados correctamente. En la identificación de la estructura cristalina, la visión por ordenador analiza eficazmente los patrones de difracción de rayos X y electrones, permitiendo la rápida identificación de fases cristalinas, la determinación de orientaciones a través del análisis de patrones Kikuchi de EBSD, y el mapeo de límites de grano. La tecnología completa estas tareas en mucho menos tiempo del necesario para analizar los cristales manualmente.
Para la detección de defectos, la visión por ordenador permite la identificación en tiempo real de fallos, que van desde dislocaciones a escala atómica capturadas en imágenes de microscopía electrónica de transmisión (TEM) hasta defectos de fabricación mayores observados en procesos de soldadura y colada. Esta tecnología tiene aplicaciones especializadas en inspecciones y capas de monitorización de obleas semiconductoras en la fabricación aditiva.
Los sistemas de visión por ordenador ya se integran a la perfección en las líneas de producción para realizar inspecciones de superficies en tiempo real, mediciones de dimensiones y decisiones automatizadas de aceptación o rechazo para el control de calidad. Estos sistemas tienen usos específicos en la industria, desde la detección de defectos en la pintura para automóviles hasta la inspección de tabletas farmacéuticas y la verificación del ensamblaje de PCB.
- Química sintética: la visión por ordenador está transformando el campo de la investigación química y la síntesis al introducir el análisis visual automatizado en diversas aplicaciones, como la supervisión de reacciones, la interpretación de diagramas y el seguimiento de compuestos. En la monitorización de reacciones, los sistemas de visión por ordenador observan en tiempo real los cambios de color, la formación de cristales y las separaciones de fases mientras analizan los patrones térmicos y las señales de fluorescencia. Esto les permite identificar los puntos finales óptimos de reacción, detectar impurezas y evitar reacciones fuera de control.
Para la interpretación de diagramas químicos, la visión por ordenador facilita la conversión de estructuras moleculares dibujadas a mano en formatos legibles por máquina. También extrae estructuras químicas de patentes y bibliografía científica, y descompone esquemas de reacción complejos para recopilar información sobre rutas sintéticas, reactivos y condiciones para el desarrollo de bases de datos y la planificación retrosintética.
En cuanto al seguimiento de síntesis de compuestos, esta tecnología se integra perfectamente con la automatización de laboratorio para supervisar síntesis en varios pasos, coordinar procesos de purificación, gestionar inventarios químicos y permitir un cribado de alto rendimiento de reacciones paralelas en placas de microtitulación. Estos avances utilizan adaptaciones personalizadas de las principales arquitecturas de visión artificial para abordar los problemas específicos de los productos químicos, como mantener la uniformidad de la iluminación para un análisis preciso del color, garantizar la compatibilidad química de los sistemas de imágenes e integrar los datos espectroscópicos y de los sensores para una comprensión más completa de los procesos.
El impacto de estas tecnologías es profundo: reducen los tiempos de optimización de reacciones de semanas a días, eliminan la subjetividad de la evaluación humana, permiten la monitorización remota de procesos peligrosos y revelan patrones visuales sutiles vinculados a resultados sintéticos exitosos. Esto representa un cambio significativo hacia una síntesis química autónoma basada en datos, que promete agilizar el descubrimiento de fármacos y optimizar los procesos de fabricación mediante el análisis visual sistemático de las transformaciones moleculares.
- Biotecnología: desde células individuales hasta intrincados tejidos, la investigación biológica implica innumerables fuentes de datos basadas en imágenes que son ideales para el análisis de visión por ordenador. El enorme volumen de células y los posibles patrones morfológicos también dificultan la identificación manual de las tendencias o anomalías, pero las soluciones impulsadas por IA pueden abordar estos desafíos y proporcionar retroalimentación en tiempo real.
Por ejemplo, los sistemas de visión por ordenador clasifican automáticamente las células y evalúan sus estados; cuantifican diversas características morfológicas, como la forma, las características nucleares y la organización citoplasmática. Además, estos sistemas pueden rastrear procesos dinámicos como la migración y la división celular, y desempeñan un papel crucial en el cribado de alto contenido para el descubrimiento de fármacos y el análisis fenotípico.
La integración de la microscopía incorpora la fusión de datos de imágenes multimodales y cuenta con sistemas de adquisición automatizados que disponen de muestreo inteligente y capacidades de cribado de alto rendimiento. El análisis en tiempo real con control de retroalimentación y las técnicas avanzadas de procesamiento de imágenes, como la deconvolución y la reconstrucción en 3D, mejoran la eficacia de la investigación. Estas aplicaciones aprovechan arquitecturas de IA especializadas, incluidos la segmentación de instancias para cultivos celulares densamente poblados, el modelado temporal para analizar datos de series temporales y el aprendizaje con pocos ejemplos para adaptarse a nuevas condiciones experimentales. También tienen en cuenta las consideraciones biológicas como la gestión de la fototoxicidad y la garantía del control ambiental.
- Alimentos y bienes de consumo: la visión artificial está transformando la seguridad alimentaria y el control de calidad con sofisticados sistemas de inspección automatizados que mantienen la integridad del producto desde la materia prima hasta el envasado final. La inspección visual es, por supuesto, un área en la que destaca esta tecnología, que puede realizar evaluaciones en tiempo real de la calidad de la superficie e identificar defectos, contaminación e incluso niveles de madurez en diversos alimentos.
La visión artificial también monitoriza varios aspectos de la calidad del procesamiento, como los niveles de cocción y la consistencia de la textura, a velocidades de producción de más de 1000 artículos por minuto. Realiza el análisis de ingredientes inspeccionando materias primas, confirmando la correcta mezcla y distribución del tamaño de las partículas, y garantizando las adiciones correctas de ingredientes. Se trata de un innovador análisis visual detallado para controlar los alérgenos, evitar la contaminación y minimizar los residuos. La tecnología también ofrece ventajas similares para la verificación de la seguridad de los envases, como garantizar que las etiquetas son legibles y que los envases están correctamente llenos y sellados.
- Agricultura y ciencias medioambientales: la visión por ordenador proporciona análisis en profundidad de imágenes satelitales y de drones, que son cruciales para la monitorización ambiental y la investigación ecológica. En el ámbito del seguimiento de la salud de los cultivos, los sistemas basados en IA analizan imágenes multiespectrales para calcular los índices de vegetación, como el índice diferencial normalizado de vegetación (NDVI), que cuantifica el verdor, la densidad y el rendimiento de la vegetación. También crean mapas de agricultura de precisión para aplicaciones de tasa variable y pronostican rendimientos mediante un seguimiento detallado del desarrollo de los cultivos a lo largo del tiempo.
La visión artificial también mejora el seguimiento de la contaminación; por ejemplo, la evaluación de la calidad del aire mediante la detección de partículas y emisiones, el control de la calidad del agua con herramientas para identificar las floraciones de algas y los derrames de petróleo, garantizar el cumplimiento industrial y realizar estudios ambientales urbanos. En la identificación de especies para estudios ecológicos, se emplean sistemas automatizados para monitorizar poblaciones de fauna silvestre y seguir migraciones. Estos sistemas también evalúan los ecosistemas marinos, detectan ballenas y monitorizan la salud de los arrecifes de coral, cartografían la biodiversidad con fines de conservación y analizan la ecología forestal para la clasificación de especies arbóreas y tendencias fenológicas.
Estas aplicaciones aprovechan tecnologías punteras como la fusión de datos multisensor, que combina datos ópticos, de radar e hiperespectrales. Emplean análisis temporales para la detección de cambios y el seguimiento de tendencias, mientras que el procesamiento de alta resolución aprovecha las redes de aprendizaje profundo entrenadas en extensos conjuntos de datos de teledetección. La integración de constelaciones de satélites y enjambres de drones garantiza una amplia cobertura, y las plataformas de computación en nube facilitan el procesamiento de petabytes de datos. Los flujos de trabajo automatizados convierten las imágenes en bruto en una valiosa información medioambiental.
Este método integral de teledetección arroja importantes beneficios, como la mejora de los rendimientos agrícolas, la reducción del uso de fertilizantes mediante aplicaciones de precisión, la mejora de la capacidad de respuesta rápida ante los desastres y las estrategias de conservación informadas. Esto representa un cambio importante hacia una gestión ambiental automatizada que apoya la investigación climática, el cumplimiento reglamentario y los objetivos de desarrollo sostenible mediante el análisis de datos de observación terrestre.
Cómo utiliza CAS la visión por ordenador
En CAS, aprovechamos el poder de la tecnología avanzada de visión por ordenador para identificar, analizar e interconectar meticulosamente la información vital extraída de nuestras fuentes de datos. La CAS Content CollectionTM es el repositorio de información científica más grande catalogado por humanos, y gran parte de lo que catalogamos va más allá del texto: estructuras moleculares reportadas presentes en numerosas fuentes documentadas como publicaciones científicas, ELN, registros internos de CAS y mucho más. Nuestro concepto de la visión por ordenador nos permite descubrir intrincados patrones y relaciones dentro de estos extensos conjuntos de datos, transformando la información bruta en percepciones significativas que impulsan la innovación y el descubrimiento.
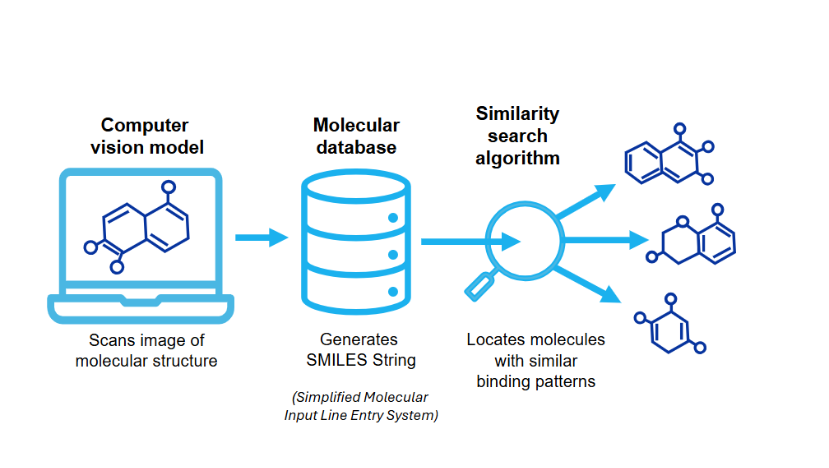
Nuestros modelos de visión por ordenador identifican y categorizan estructuras moleculares, mejoran los algoritmos de búsqueda y extraen datos valiosos de contenidos científicos complejos (véase la figura 1). Además, interpretan y analizan hábilmente los resultados experimentales que se resumen en tablas detalladas, proporcionando información completa de los hallazgos científicos subyacentes. Incorporamos estas capacidades para enriquecer la colección de contenidos de CAS y ayudar en el análisis posterior.
Al conectar los puntos de datos extraídos con contenidos estructurados y ontologías, simplificamos el acceso a información crucial y capacitamos a los científicos para tomar decisiones más rápidas y fundamentadas.
Pasos clave para desarrollar un plan de visión por ordenador
Para desarrollar un modelo sólido de visión artificial:
- Defina claramente el problema y recopile un conjunto de datos diverso y detallado.
- Preprocese los datos redimensionando, normalizando y ampliando lo que tiene. Esto debe hacerse antes de dividir los datos en conjuntos de entrenamiento, validación y prueba.
- Evalúe su oferta tecnológica en esta fase inicial. Su hardware necesitará GPU capaces de agilizar el entrenamiento y la inferencia de modelos de aprendizaje profundo.
- Tenga siempre en cuenta las consideraciones éticas, para garantizar que el modelo cumpla las normativas sobre sesgo y privacidad.
- Elija la arquitectura modelo adecuada para el entrenamiento y, a continuación, evalúe su rendimiento con las métricas adecuadas en el conjunto de datos de prueba e implementando las mejoras iterativas según sea necesario.
- Implemente el modelo en un contexto del mundo real, supervise su rendimiento y planifique posibles reentrenamientos debido a la deriva de datos a medida que las industrias, los dominios específicos y los objetivos empresariales cambian con el tiempo.
- Céntrese en el escalado, la optimización y la documentación de la arquitectura del modelo y los procesos para las futuras consultas y para compartir conocimientos dentro de su equipo.
La clave del éxito es involucrar a expertos en la materia en cada etapa. Se necesitan conocimientos interdisciplinarios para ayudar a comprender los matices del dominio, identificar los datos relevantes, dirigir la anotación de datos, validar la calidad de los datos e interpretar los resultados del modelo.
Como todas las tecnologías basadas en IA, la visión por ordenador seguirá evolucionando, y los modelos que aprovechan sus capacidades se perfeccionarán con el tiempo. La importancia de esta tecnología para todos los ámbitos de la investigación científica crecerá, y con avances más rápidos en campos como el descubrimiento de fármacos o la ciencia medioambiental; así, podremos responder con mayor eficacia a los desafíos a los que se enfrenta nuestro mundo.




